第四章 数据类型
1.22 整数型
数值型(numeric type),包括整型和浮点型
1.整数类型的创建方法、取值范围和运算应用
2.认识函数
8位整数int8
无符号8位整数uint8(其他见下表)
取值范围intmax/intmin
测试类型class
3.概念
Matlab支持整数数据的1个,2个,4个和8个字节的存储,再分为有符号和无符号,总共8个整型类别。
整型类型
|
整型类别 |
取值范围 |
函数 |
|
有符号的8位整数 |
-2^7至2^7 -1 |
int8 |
|
有符号的16位整数 |
-2^15至2^15 -1 |
int16 |
|
有符号的32位整数 |
-2^31至2^31 -1 |
int32 |
|
有符号的64位整数 |
-2^63至2^63 -1 |
int64 |
|
无符号的8位整数 |
0到2^8 -1 |
uint8 |
|
无符号的16位整数 |
0至2^16 -1 |
uint16 |
|
无符号的32位整数 |
0至2^32 -1 |
uint32 |
|
无符号的64位整数 |
0到2^64 -1 |
uint64 |
4.实例演示
%1_22
int8(10) %有符号整型
int8(10.5) %只能存储整数、四舍五入
intmax('int8') %获取有符号整型最大值127
intmin('int8') %获取有符号整型最小值-128
intmax('uint8')
intmin('uint8')
int8(130) %130超出最大值范围,则返回最大值127
int8(500) %返回127
int8(-130) %-128
int8(1)*int8(5) %整型运算:结果为整型5
int8([1 2 3])*int8(5) %整型数组,遵循兼容性运算
a=int8([1 2 3])*2.3 %整型数组*双精度浮点型,四舍五入存储整数
class(a) %测试a类型,int81.23 浮点型
1.浮点型的创建和转换方法、取值范围、运算和精度问题
2.认识函数
双精度double
单精度single
判断浮点型isfloat
取值范围realmax/realmin
精度eps
3.说明
浮点型分为单精度浮点型和双精度浮点型
IEEE浮点数算术标准(IEEE 754)是IEEE二进位浮点数算术标准(IEEE Standard for Floating-Point Arithmetic)的标准编号,等同于国际标准ISO/IEC/IEEE 60559。该标准由美国电气电子工程师学会(IEEE)计算机学会旗下的微处理器标准委员会(Microprocessor Standards Committee, MSC)发布,是最广泛使用的浮点数运算标准,为许多CPU与浮点运算器所采用。
知识扩展:这个标准定义了表示浮点数的格式(包括负零-0)与反常值(denormal number),一些特殊数值(无穷与非数值(NaN)),以及这些数值的“浮点数运算子”,它也指明了四种数值修约规则和五种例外状况(包括例外发生的时机与处理方式)。
任何存储为double格式的值都需要64位。
double类型
|
位 |
用法 |
|
63 |
符号(0=正数,1=负数) |
|
62 至 52 |
指数 |
|
51 至 0 |
小数位(分数位) |
任何存储为single格式的值都需要32位。
single类型
|
位 |
用法 |
|
31 |
符号(0=正数,1=负数) |
|
30 至 23 |
指数 |
|
22 至 0 |
小数位(分数位) |
4.浮点型的精度问题
Matlab中几乎所有的运算默认都是以符合IEEE 754标准的双精度算法执行的,由于计算机只能以有限的精度表示数字(双精度要求52个尾数位),对于数值运算,这种浮点型表示值与其真实值存在微小的差异
所以,如果浮点算术运算的结果不如预期的那样精确,甚至有时会产生数学上非直觉的结果,则很可能是由于计算机硬件的限制造成的,硬件可能没有足够的位来表示结果的完全准确性,因此截断了结果值的部分精度(例如32位的电脑)
但这并不是Matlab中的错误,运用IEEE 754标准所执行的所有计算都受到影响,其中包括用C或FORTRAN等
5.实例演示
%1_23
%freexyn
double(1) %创建双精度浮点型1
a=1 %默认双精度浮点型,再赋值给a
isfloat(a) %判断是否浮点型
class(a) %测试变量a的数据类型
whos a %测试变量a的数据类型等信息
single(1) %单精度1
realmax('double') %双精度浮点数的最大取值
[-realmax,-realmin,realmin,realmax] %完整的双精度浮点型取值范围(-0和0之间取不到任何值)
[-realmax('single'),-realmin('single'),realmin('single'),realmax('single')] %单精度浮点型取值范围,上式未指定则默认取双精度浮点型范围
%% 浮点型与整型转换方法
c=int8(1) %整型1
c1=double(c) %整型c转化为双精度,数据类型创建方法也是转化方法
c2=single(c) %转化为单精度
int8(c1) %双精度转化为整型
whos c c1 c2 %查看数据类型:双精度8字节精度最高
%% 精度问题相关
sin(pi) %会保留部分精度的小数再进行计算,因此结果会有误差(计算机有限位数存储有限精度)
sin(sym(pi)) %sym将pi转化为符号型再求sin值,结果是0更精确
eps %默认求1的精度,求得的值为1附近的误差值
1
1+eps %结果1,因为硬件所限导致的精度问题,无法表达eps更小的值
eps(10) %求10附近的精度
eps(100) %求100附近的精度
eps(single(100)) %单精度100附近的精度
(4/3-1)*3-1 %4/3并非完整精确的分数,而是有限存储空间内的近似值,因此结果并非0
(sym(4/3)-1)*3-1 %返回0,引入符号型获得精确4/3值1.24 Inf和NaN
1.介绍inf和nan的含义和用法
2.认识命令
无穷大inf
非值nan
判读无穷大isinf
判断非值isnan
3.说明
用特殊值“inf”表示无穷大,比如零除和溢出等这样的运算会产生无穷大,这导致结果太大而不能用传统的浮点值表示
用特殊值“NaN”表示既不是实数也不是复数的“非数字”的值
Matlab里,inf与inf相等判断为真,nan与nan相等判断为假
4.实例演示
%1_24
realmax %浮点型最大取值
realmax+1e30 %最大取值再加上10^30并未返回无穷大值
realmax+1e300 %加上10^300返回无穷大值。说明:10^30相对于realmax较小,因此忽略;10^300相对于realmax不能忽略。
a=inf
1/0 %无穷大
1e309 %超过存储范围,返回无穷大
isinf(exp(1000)) %返回逻辑1,判断无穷大
inf==inf %1真
inf+10 %返回Inf
inf-1e308 %返回Inf
inf+inf %返回Inf。
inf/inf %nan。无穷大参与的运算,结果通常为无穷大,仅本情况例外
0/0 %nan
a=nan %nan
isnan(a) %nan
nan==nan %假
nan>0
nan<0
nan~=nan %涉及nan的关系运算结果通常为假1.25 显示格式
1.设置命令行窗口数值的显示格式
2.认识函数
format
3.说明
数值格式仅影响数字显示在命令行窗口输出中的方式
而不是 Matlab计算或保存它们的方式
指定的格式仅应用于当前 Matlab会话
4.实例演示
%1_25
a=[1/3 1.23e-5] %默认显示4位小数
format short %短格式默认5位
a
format long %长格式默认15位
a
format short e %科学计数法
a
format rational %有理数
a
format hex %16进制
a
format shortG %短格式基础上紧凑格式
a
get(0,'format') %获取当前格式,0为句柄值,表示当前会话
set(0,'format','short') %set设置格式为short
a
format short
format %short为默认格式,因此可不打出来1.26 字符型
在Matlab中有两种表示文本的方法:字符型和字符串型
1.字符型(Characters)数组的创建、连接、转换和运算
2.认识函数
字符型 ''
判断字符型ischar
转成字符char
转成字符num2str
转成数值str2num
交集intersect
并集union
3.说明
字符型一般用来存储和处理文本数据
字符数组是一个字符序列
字符向量把字符存储为1乘n的向量,是常用形式
4.实例演示
%1_26
a='123' %创建3个字符数组
b='freexyn'
c='自由未知数'
size(c) %查看行列数
ischar(a) %判断字符型
'I''m fine' %字符型内单引号处理:改用双引号('')
c(1:3) %索引字符向量的元素
c(6)='.' %通过索引修改字符向量的元素
[b,c] %字符连接:中括号水平连接
strcat(b,c) %水平连接函数
strvcat(b,c) %垂直连接函数:若列数不同自动使用空格补齐
char('d') %字符d转换(创建)为字符型
'd' %通常使用该方法
char(100) %双精度转换为字符型:基于Unicode码
char([97 98 99 100]) %转换1行4列的数值向量,结果a b c d
double('a') %将字符型a转换为双精度数值型
char('12','0') %char函数输入多个参数时,会将其纵向连接为多行,并相应转换为字符型
char('12',100)
char('12',100,'123')
char(['12',100],'123') %参数用中括号括起来表示在同一行
char(100) %转换为字符d:根据unicode码
num2str(100) %‘100’,把100转化为'100'字符型
str2num('100')
r=80
disp(['r:',num2str(r)]) %打印(显示)信息:r:80,数值跟随变量自动变化
%% 字符型数字运算
a='d'
b='100' %1行3列字符向量:1 0 0
a+a %字符型加法:首先转换成数值型,再运算,返回结果200
a+b %1 0 0字符向量按ASCII码转换为数值型分别为49 48 48,再分别与d转换的100相加,返回149 148 148
char(49) %数值型转化为字符型:'1'
str2num('100')+str2num('100')
%% 集合运算
a='123' %字符向量
b='1245'
union(a,b) %并集
intersect(a,b) %交集1.27 特殊字符
1.特殊字符识别和处理
2.认识函数
判断字母isletter
判断空格isspace
判断特定字符isstrprop
空字符blanks
字符调整strjust
删除空格deblank
删除空格strtrim
3.实例演示
%1_27
a='abc 123'
isletter(a) %判断字母
isspace(a) %判断空格
find(isspace(a)) %对空格进行线性索引
a(find(isspace(a)))=[] %将a字符中的空格删除
%% 判断特定字符
b='12 ab_AB, '
isstrprop(b,'alpha') %判断特定字符 字母
isstrprop(b,'lower') %判断特定字符 小写字母
isstrprop(b,'upper') %判断特定字符 大写字母
isstrprop(b,'digit') %判断特定字符 数字
isstrprop(b,'punct') %判断特定字符 标点
isstrprop(b,'wspace') %判断特定字符 空格
%% 空字符的处理
c=blanks(7) %创建空字符函数,创建7个空字符
c(3:5)='aaa'
strjust(c,'left') %strjust字符调整,将c中空字符调至左边
deblank(c) %删除尾随空字符
strtrim(c) %删除前后空字符,但不删除中间的空字符1.28 混合连接的类型
1.多个类型的数据混合连接后的数据类型
2.组合类型列表
组合类型列表
|
类型 |
字符型 |
整型 |
单精度 |
双精度 |
逻辑型 |
|
字符型 |
字符型 |
字符型 |
字符型 |
字符型 |
无效 |
|
整型 |
字符型 |
整型 |
整型 |
整型 |
整型 |
|
单精度 |
字符型 |
整型 |
单精度 |
单精度 |
单精度 |
|
双精度 |
字符型 |
整型 |
单精度 |
双精度 |
双精度 |
|
逻辑型 |
无效 |
整型 |
单精度 |
双精度 |
逻辑型 |
3.说明
总体上,除逻辑型外,连接后的类型遵循向下转换的原则
逻辑型除了与自身连接是逻辑型,与其他连接转换成其他型
4.实例演示
%1_28
[100 single(100)]
[100 single(100) int8(100)]
[100 single(100) int8(100) 'd']
[100 true] %双精度与逻辑型连接
%% 整型内部连接
[int8(100) int16(100)]
[int16(100) int8(100)] %遵循最左侧整型类型的原则
[int8(-100) uint8(100)]
[uint8(100) int8(-100)] %右边由有符号变为无符号,仅取到最小值0
%% 混合连接
[true pi int32(10) single(1.23) uint8(345)] %pi为双精度,int32为整型,混合连接遵循最左侧整型数据类型原则,后面超出int32的数据会相应变化
[true pi single(1.23) uint8(345)] %结果取uint81.29 混合运算的类型
1.多个类型的数据混合运算后的数据类型
2.混合运算类型列表
混合运算类型列表
|
运算数类型 |
运算数类型 |
结果类型 |
|
double |
int(uint) |
int(uint) |
|
single |
single |
|
|
double |
double |
|
|
char |
double |
|
|
logical |
double |
|
|
single |
single |
single |
|
char |
single |
|
|
logical |
single |
3.说明
总体上,除逻辑型和字符型,混合运算类型遵循向下转换的原则
逻辑型除了与自身运算是逻辑型,与其他运算转换成其他型
4.实例演示
%1_29
%freexyn
%% 混合运算
10+single(10) %双+单=单
10+int8(10) %双+整=整
%[10 10]+int8(10) %双精度数组无法与整型相加,报错
10+'d' %双精度+字符型=双精度
'd'+'d' %字符型+字符型,先转换为双精度再运算
[10,'d'] %复习上节,连接:[双精度 字符型] =字符型
10+true %双精度+logical=双精度
%% 整型内部运算
% int8(10)+int16(10) %不同类型整型无法相加运算
[int8(10),int16(10)].*[int8(10),int8(10)] %整型数组乘法
% [int8(10),int16(10)]*[int8(10);int8(10)] %矩阵乘法,前面列数等于后面行数,报错:矩阵乘法不完全支持整数类,仅支持参数之一为标量的情况1.30 字符串型
1.字符串(Strings)数组的创建、比较、索引和运算
2.认识函数
创建strings
判断isstring
字符串长度strlength
3.说明
字符串是一个字符序列,常见的,存储一个1乘n的字符向量
字符串数组是由多个字符串作为元素组成的数组
从Matlab2016b开始,可以使用字符串类型
从2017a开始,可以使用双引号创建字符串
4.实例演示
%1_30 字符型创建、比较、索引和运算
%% 字符串和字符数组的创建
s="自由未知数" %字符串
isstring(s) %判断字符串型
ischar(s) %判断字符型
s=["123","abcd";"自由未知数","%$%#"] %字符串数组
strings(2,3) %创建字符串数组函数,2行3列空字符串数组
strings(0,3) %空的0*3数组
%% 字符型的比较
c='' %空字符向量
s="" %1*1字符串
size(c)
size(s)
isempty(c)
isempty(s)
c='freexyn' %字符向量(数组)
s="freexyn" %1*1字符串
size(c)
size(s)
%% 字符型的连接
['123','ab'] %字符向量连接,结果为更大的字符向量
["123","ab"] %字符串连接,结果为字符串数组
%['123';'ab'] %行数列数不同,报错
["123";"ab"] %可行
%% 补充
length(c) %字符向量长度
length(s) %字符串数组长度
strlength(s) %字符串元素的长度
%% 字符串型索引
s=["123","abcd";"自由未知数","%$%#"]
s(1,2) %常规组合索引
s{1,2} %索引字符串的元素内容,返回字符向量
s{1,2}(1:2) %索引元素内容后,用二级索引获取子段
%% 字符串型运算
s+"x" %视为矩阵添加标量,添加到每个元素中
s+'x' %结果同上1.31 缺失字符串
1.字符串的转换、缺失字符串的创建和应用
2.认识函数
转换string
缺失值missing
判断缺失ismissing
3.说明
缺失值表示数据中不可靠或不可用的点
不同类型中缺失值的表达不同,数值型用NaN,字符串里用<missing>
missing从Matlab2017a开始推出
字符串数组扩展时,缺失元素用<missing>自动填充
4.实例演示
%1_31
%% 字符串的转换
string(100) %双精度转换为字符串型
char(100) %双精度转换为字符型,依据Unicode码操作
string('100') %字符型转换为字符串型
char("100") %字符串型转化为字符型
%% 缺失值
missing %通用的缺失值函数,适用于任何类型
string(missing) %将missing转化为字符串类型的缺失值
ismissing(["","abc",string(missing)]) %判断数组3个元素是否为缺失值
string(missing)==string(missing) %缺失值与任何数值比较都为假,除特例比较不相等
string(missing)=="x"
string(missing)~=string(missing) %特例
%% 缺失值的运算
string(missing)+string(missing) %缺失值的任何运算结果都是缺失值
string(missing)+"x"
%% 字符串数组的扩展
s="x" %创建字符串数组
s(2,3)="x" %扩展为2行3列的数组,并将第2行第3列元素赋值为''x''1.32 格式化文本
1.简单介绍格式化文本的用法
2.认识函数
sprintf
3.说明
格式化文本,是具有特定显示格式的文本形式,包括字段宽度、显示精度、特殊标志和辅助符号等
普通文本和数值需要按照特定格式显示和输出时,会用到
示例,sprintf('|%f\n|%.2f\n|%8.2f',pi*ones(1,3))
4.实例演示
%1_32
sprintf('|%f\n|%.2f\n|%8.2f',pi*ones(1,3)) %第一个参数为格式设置,第二个参数为对应的数值,此处,3组格式设置对应3个值
%每行起始为竖线|,%是必须的字段,f代表浮点型,将浮点型值转化为文本,\n为转义符代表回车
%.2代表小数点后保留2位精度
%8.2总长度8,小数点后保留2位,长度不够时按实际长度1.33 字符型与数值型的转换
1.字符型和数值型之间的相互转换
2.认识函数
字符转数值uintN %依据Unicode码转换
数值转字符char %依据Unicode码转换,ASCII码与Unicode码并非相同概念,ASCII较基础,应用范围小,主要表示键盘上字母符号等,Unicode码包含ASCII码,囊括多国语言字符。
数值转字符串string
字符转数值str2num、str2double
数值转字符num2str、int2str
十和二进制互换bin2dec、dec2bin
十和十六进制互换hex2dec、dec2hex
十和其他进制互换base2dec、dec2base %十进制必然是数值型,其他任意进制都使用字符型表达
3.实例演示
%1_33
%% 字符与数值转换
uint8('ab') %字符'ab'转换为8位整型的整数
uint16('ab') %字符'ab'转换为16位整型的整数
uint8('是') %ASCII无汉字,Unicode包含
uint16('是')
2^16 %16位最大值
uint32('是')
%相反功能
char([97 98]) %数值转换为字符型
string([97 98]) %转换成字符串数组
%% 字符型转换为数值型
str2num('100') %字符向量转换为数值型
str2double('100') %同上
str2num("100") %字符串转换为数值型
str2double("100") %同上
%str2num(["100","100"]) %该函数无法将字符串数组转换为数值型
str2double(["100","100"]) %字符串数组转换为数值型
%相反功能:数值转换为字符
num2str(100) %双精度数值转换为字符
num2str(1.2345,3) %第2个参数设置前面转换后保留的精度
num2str(100,'%5.2f') %格式化文本,单引号中进行设置
int2str(1.23) %浮点型转为字符
%% 不同进制之间转换
bin2dec('1000') %二进制转换为十进制
dec2bin(8) %十进制转换为二进制
hex2dec('A') %十六进制的A转换为十进制
dec2hex(10) %十进制转换为十六进制
base2dec('10',2) %任意进制转换为十进制:'10'为转换数值,2为二进制
base2dec('10',8) %八进制的10转化为十进制
base2dec('10',20)
dec2base(2,2) %十进制的2转化为二进制
dec2base(8,8)
dec2base(9,8) %十进制的9转化为八进制1.34 元胞数组
1.元胞数组的创建、索引和转换方法
2.认识函数
创建方法:a={}和cell (与Python中字典结构相似)
判断iscell
索引()和{}
转换cell2mat、mat2cell
3.概念
元胞数组(cell array)是一种具有容器特性的数据类型,每个元素可以包含任何类型的数据
4.说明
元胞数组创建和扩展时默认填充元素是空矩阵[]
元胞数组不需要完全连续的内存,但每个元素需要连续的内存
对大型的元胞数组,增加元素数量可能导致Out of Memory错误
因此,必要时,元胞数组需要初始化和预分配内存
5.实例演示
%1_34
%% 元胞数组创建、2种预分配内存方法
a={}
b={1,2,magic(3)
'a',["a","b"],[]} %分别双精度标量、3阶魔方矩阵、字符、字符串数组、空矩阵。2行用回车分割,或用分号分割
cell(2,3) %创建2行3列元胞数组
c=cell(100,100) %对大型元胞数组,预分配内存
d={} %初始化后(也可不初始化,因Matlab使用变量不需提前声明,因此也可直接赋值)
d{100,100}=[] %用数组扩展的方式,将第100行第100列元素设置为空,其他未指定元素默认用空矩阵填充,完成预分配内存
iscell(a) %判断元胞数组
%% 元胞数组索引方法(可类比字符串数组索引)
b(1,3) %索引元胞数组的元素
b{1,3} %索引元胞数组的元素的内容
b{1,1:3} %索引1行1-3列元素,未指定输出变量,默认ans
[v1,v2,v3]=b{1,1:3} %索引3个元素值,并赋值给3个变量
v=b{1,1:3} %当仅指定1个输出变量,则只返回第1个值
b{1,3}(1:2) %二级索引
%% 元胞数组数据连接
%[b{1,1:3}] %维度不同无法连接
[b{1,1:2}] %2个索引到的元素,连接为1*2矩阵
%% 元胞数组转换:每个元胞元素类型相同且大小相同才可转换
%cell2mat(b) %b没有明确结果类型因此报错
m=cell2mat({1 2}) %数值型可以转换为矩阵
n=cell2mat({'a','b'})
%cell2mat({"a","b"}) %该转换函数不支持字符串数组
mat2cell(m,1) %第2个参数1表示1行1列元胞数组,将整个矩阵看做元胞数组元素
mat2cell(m,1,[1 1]) %第3个参数指定了列数为2列,每列个数分别为1
mat2cell(n,1)
mat2cell(n,1,[1 1])1.35 元胞数组的修改
1.元胞数组的修改、添加、删除和连接
2.认识函数
连接[]和{}
3.说明
元胞数组的子数组或元素也是元胞型的,其元素内容是本身类型
4.实例演示
%1_35
%% 元胞数组修改
b={1,2,magic(3)
'a',["a","b"],[]} %理解:元胞数组是大箱子,用大括号表示,内部的元素是盒子,盒子也是元胞型,盒子与箱子遵循Matlab预设规则,能修改的就是打开盒子往里面装内容,内容可以是任意大小任意格式的内容。
% b(1,1)=100 %元胞数组数据修改,小括号索引出第1行第1列元胞型,100双精度型无法赋值(小括号索引到盒子),报错
b(1,1)={100} %赋值也应包装成盒子(元胞型)再赋值
b{1,1}=100 %(大括号索引到盒子的内容)所以使用任意数值赋值即可
%% 元胞数组添加、删除
b(3,4)={8} %b本身是2行3列,如此扩展为3行4列,第3行第4列为{8}其余扩展元素默认空矩阵填充
% b(1,1)=[] %报错,删除1个元素无法保持矩阵矩形
b(end,:)=[] %最后一行删除,可行
b{1,1}=[] %大括号索引到盒子里的内容,并置为空(删除),盒子仍存在
%% 元胞数组连接
%中括号连接:把元胞数组打开重排
[{1 2 3},{'a'}] %水平连接
% [{1 2 3};{'a'}] %列数不同,报错
[{1 2 3};{'a',[],[]}] %列数相同
%大括号连接:元胞数组视为整体重排(可理解为元胞数组的嵌套,元胞数组内可容纳任意类型,包括元胞型自身)
{{1 2 3},{'a'}} %水平连接
{{1 2 3};{'a'}} %纵向排列
{{1 2 3},{'a'},{},[],string(missing),uint16(10)} %只要占用元胞数组内的盒子,都会显示1.36 结构数组
1.结构数组的创建、索引和预分配内存
作者:freexyn(整理/注释:韩松岳)
2.认识函数
创建struct
判断isstruct
运算符 .
3.概念
结构(structure array)是一种具有容器特性的数据类型,它使用称为字段的数据容器对相关数据进行分组,每个字段可以包含任何类型或大小的数据。(与元胞数组描述类似,都是容器型数据类型,组织结构不同)


包含1个元素的结构数组
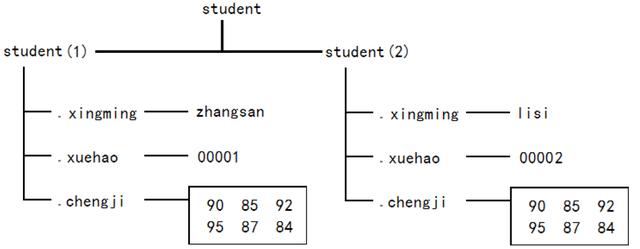
包含2个元素的结构数组
4.创建方法(2种方法)
数组名.字段名=字段值,遍历所有字段名赋值
数组名=struct(‘字段名’,‘字段值’…)
5.说明
所有元素都具有相同数量的字段和相同的字段名称
字段未指定的默认值为[](默认为空矩阵,与元胞数组相同)
结构数组不需要完全连续的内存,但每个字段需要连续的内存
对于大型的结构数组,增加字段的数量或字段中数据的数量可能会导致Out of Memory错误
因此,必要时,结构数组需要初始化和预分配内存
6.实例演示
%1_36
%% 单元素结构数组创建
%方法1:(分别列出字段信息,元素名与字段信息用圆点(.)分隔)
student.xingming='zhangsan'; %student是结构数组名,后跟字段名,等号右侧为字段值
student.xuehao='00001';
student.chengji=[1 2 3;4 5 6]
%方法2:(struct函数创建,分别列出每条字段信息,最后赋值给变量名)
stu=struct('xingming','zhangsan','xuehao','00001','chengji',[1 2 3;4 5 6])
%单元素结构数组的操作
isstruct(stu) %判断结构数组
stu.chengji %字段索引
stu.chengji(1:3)%2级索引,与元胞数组类似
%% 多元素结构数组
%方法1:(在前面基础上添加)
student(2).xingming='lisi';
student(2).xuehao='00002';
student(2).chengji=[7 8 9;1 2 3]
%方法2:
stu(2)=struct('xingming','zhangsan','xuehao','00001','chengji',[1 2 3;4 5 6])
%多元素结构数组操作
student.chengji %若不指定哪个元素,则显示所有该字段名的值
student(2).chengji %指定第2个元素,显示该元素的该字段值
% student.chengji(1:3) %2个及以上元素的结构数组不能直接使用二级索引,因未指定元素,无法确定索引的结果
student(2).chengji(1:3)
%预分配内存
st(100,100)=struct('a',[]) %边界思想,设置结构数组的边界元素为字段名为'a'且字段值为[]的结构数组,其他元素值默认填充为空[]
st.a %索引st的字段'a',返回100个空矩阵1.37 结构数组的处理
1.结构数组的连接、嵌套、引用变量值和访问字段值
2.说明
结构数组必须具有相同的字段名才能连接,元素数目可以不同
为某元素添加字段,其他所有元素也具有了该字段,默认值为[]
3.实例演示
%1_37
%作者:freexyn
%创建3个结构数组student/stu/st
student.xingming='zhangsan';
student.xuehao='00001';
student.chengji=[1 2 3;4 5 6];
stu=struct('xingming','zhangsan','xuehao','00001','chengji',[1 2 3;4 5 6]);
student(2).xingming='lisi';
student(2).xuehao='00002';
student(2).chengji=[7 8 9;1 2 3]
stu(2)=struct('xingming','zhangsan','xuehao','00001','chengji',[1 2 3;4 5 6])
st(100,100)=struct('a',[])
%% 结构数组的连接
[student,stu] %同为1*2结构数组,并且字段名相同,结果为1*4结构数组
% [student,st] %维度不同且字段名不同,报错
%% 嵌套
student(1).stu=stu %嵌套,理解:创建字段名stu,并把原结构数组stu作为字段值赋值给该字段名。给结构数组student的第1个元素student(1)添加stu字段,其他所有元素(如student(2))也会具有该字段
student(1).stu %索引,查看第1个元素的stu字段名里的字段值(字段内容),结果为原stu数组
student(2).stu %索引,结果是空矩阵,因为未指定该字段的值
%多级索引打开内部嵌套的字段值(理解:结构数组的索引,用圆点运算符(.)层层打开字段值,访问所需内容)
student(1).stu(1) % student第一个元素的stu字段的第一个元素的值
student(1).stu(1).chengji %进一步获取该元素的chengji字段的值
student(1).stu(1).chengji(1:3) %进一步获取成绩值的第1-3元素
%% 预留字段(添加新字段)
yuliuziduan='nianling' %通过预留变量名的形式,给元素添加字段,字段名的赋值需字符型。
stu(1).(yuliuziduan)='nan' %给包含多个元素的结构数组通过小括号+预留变量名的方式添加字段时,要指定具体元素,等号右侧赋字段值
%用途:当后面需要修改字段名时,不需再每处修改,而只修改预留变量所赋的值即可,树状图思想,预留变量作为中间值
stu(1).(yuliuziduan) %小括号引用该预留变量代表的字段名,并索引该字段名的字段值,即nan
%% 获取结构数组字段值
student.chengji %索引student所有元素的chengji字段的值
v=student.chengji %当只有一个输出参数v时,只返回第1个值
[v1,v2]=student.chengji %若返回所有字段值,则指定相同个数的输出参数
v=[student(1).chengji,student(2).chengji] %将多字段值存储在同一矩阵中,则先将字段值提取再矩阵连接。要求字段值数据类型相同,横纵连接符合矩阵连接的维度要求1.38 表
1.表类型数据的创建、索引和自身属性的用法

3*3 table数组
2.认识函数
创建table
判断istable
属性.Properties
3.概念
表(table)具有容器特性的数据类型,可以方便的存储混合类型的数据,可以使用数字或命名索引访问数据以及元数据(例如变量名称,行名称,描述和变量单位等)
4.说明
表由行和列组成
通常,表的列代表不同的变量,行代表不同的变量值
不同变量须具有相同数量的变量值,即行数须相同,否则不完整
表的索引方法有两种,下标索引和字段索引
5.实例演示
%1_38
%% 表格创建
xingming={'zhangsan';'lisi';'wangwu'} %用元胞数组的形式,创建表的每一列
xuehao={'1001';'1002';'1003'}
chengji=[89 95;90 87;88 84]
t=table(xingming,xuehao,chengji) %表格的创建:table函数+小括号输入变量
istable(t) %判断
%% 表格索引
t(1:2,2:end) %下标索引:1-2行,2-最后一列
t.xingming %字段索引:索引该字段(列名称)所指向的整列数据
t.chengji(2,1) %组合索引:成绩字段里第2行第1列
t.age=[20;19;21] %使用字段索引为表格添加变量(字段)名称,并赋值。默认添加至最后一列
size(t) %表格维度
%% 表格属性的应用
t.Properties %.表格的属性数据,是结构数组
t.Properties.VariableNames %二级索引获取属性里的变量名称
t.Properties.RowNames={'1','2','3'} %给行名称赋值。注:赋值应与属性值数值类型相同(属性是元胞数组,则赋值也以元胞数组形式)
%用途:赋予行名称后,可以作为索引使用
t('1','xuehao') %索引1行xuehao列的数据,形式类似于下标索引,下标即矩阵下标ij,而该索引以行与列的名称索引。
t(1,2) %下标索引,1行2列
t({'1','2'},{'xingming','age'})1.39 表的数据处理
1.表的编辑(排序查找提取删除)、计算、与结构数组转换
2.认识函数
统计summary
与结构数组转换table2struct、struct2table
与元胞数组转换table2cell、cell2table
3.实例演示
%1_39
xingming={'zhangsan';'lisi';'wangwu'};
xuehao={'1001';'1002';'1003'};
chengji=[89 95;90 87;88 84];
t=table(xingming,xuehao,chengji)
%% 表格的统计
summary(t) %无法统计字符型元胞数组,可以对chengji双精度型进行统计处理(按列统计)
mean(t.chengji) %字段索引再mean函数(默认维度按列即字段名求均值)
mean(t.chengji,2) %2表示第2维度即按行求均值
t.pingjunzhi=mean(t.chengji,2) %使用字段索引并赋值
%% 表的排序、查找
sortrows(t,'xingming') %按行排序,表格t按字段'xingming’按字母升序
t(:,[1 2 4 3]) %用索引排序:任意行,列将3和4列互换
% t.pingjunzhi=[] %删除,用字段索引赋空值删除该列
tf=t.pingjunzhi>90 %查找平均值大于90的学生信息,返回逻辑值;
t(tf,:) %使用tf作为逻辑索引,索引表格中符合条件的学生的信息
%% 数据转换
t
s=table2struct(t) %表格转换为结构数组后,每一行都变为1个元素,因此是3行1列的结构数组
s(1) %查看第1个元素的值
struct2table(s) %反向转换
c=table2cell(t) %表格转换为元胞数组后,变量名称消失,变量值转换为元胞数组,其中多列的双精度值会自动拆分为多个单列表示
cell2table(c) %反向转换1.40 表的读入写出
1.表与外部文件的读入和写出
2.认识函数
读入readtable
写出writetable
3.实例演示
%1_40
xingming={'zhangsan';'lisi';'wangwu'};
xuehao={'1001';'1002';'1003'};
chengji=[89 95;90 87;88 84];
t=table(xingming,xuehao,chengji)
writetable(t,'student.txt') %写出数据到txt文件
stu=readtable('student.txt') %从txt文件读入数据
stu.chengji=[stu.chengji_1,stu.chengji_2] %上面写出再读入后,多列数据自动拆分,把拆分后的数据恢复成原先数据
stu.chengji_1=[]
stu.chengji_2=[]
writetable(t,'student.xls') %写出数据到Excel文件
stu=readtable('student.xls') %从Excel文件读入数据1.41 日期时间型
1. 日期时间型的概念及其简单应用
2.认识函数
日期时间datetime
持续时间duration
3.概念
日期时间型(Dates and Time)数据具有灵活的显示格式和高达毫微秒的精度,并且可以处理时区、夏令时和平闰年等特殊因素
日期时间型数据有以下三种表示方式
Datetime型,表示日期时间点,是存储日期和时间数据的主要方法,它支持算术运算,排序,比较,绘图和格式化显示
Duration型,表示日期时间的持续长度
CalendarDuration型(略)
4.实例演示
%1_41
%freexyn
datetime(2018,8,8) %创建日期时间型,输入参数为:年、月、日
t=datetime(2018,8,8,12,0,0) %输入参数为:年、月、日、时、分、秒
d=duration(3,2,0) %创建持续时间型,时长3小时2分0秒
years(1)
days(1)
hours(1)
%% 运算
t2=t+d %时间点和持续时间的运算结果仍为时间点
t3=t-d
t-days(4)
hours(1)+minutes(30)
t2>t %时间点的比较,时间越晚,则越大
t3>t
hours(1)>minutes(30) %持续时间的比较,时间越长,则越大
%% 显示格式
t %时间点的显示格式设置
datetime(t,'Format','y-MM-dd') %时间点显示格式,使用format属性设置
datetime(t,'Format','y-MM-dd HH:mm:ss eeee') %y M d H m s e分别代表年、月、日、时、分、秒、星期
d %持续时间显示格式设置
duration(d,'Format','m') %m表示分钟,另外,h表示小时、s表示秒
%% 补充
[y m d]=ymd(t) %函数ymd获取时间点t中的年月日信息赋值给相应变量,另外,时分秒hms同理
dateshift(t,'start','day',0:2) %时间推移方法获取时间序列,start表示返回一天的起点即0点,0:2推移2天
char(t) %日期时间型转换为字符型,转换后可用字符型规则处理数据
NaT %datetime型的数据,表示非时间,即缺失值。1.42 缺失数据的处理
1.各类型缺失数据的创建、判断、替换、移位和处理方法
2.认识函数
替换standardizeMissing
替换为fillmissing
位置'MissingPlacement'
忽略'omitnan'
移除rmmissing
3.实例演示
%1_42
%% 各类数据缺失值的创建
a=[nan 1 2 3] %数值型缺失值
s=[string(missing) "a" "b"] %字符串型缺失值
t=[NaT datetime(2018,8,8)] %时间型缺失值
%missing函数可创建不同数值类型的缺失值
aa=[missing 1 2 3]
ss=[missing "a" "b"]
tt=[missing datetime(2018,8,8)]
isnan(a) %判断数值型
ismissing(a) %判断缺失值
ismissing(s)
ismissing(t)
%% 缺失值的替换
standardizeMissing(a,[2 missing]) %变量中参数替换为缺失值
standardizeMissing(s,["b" missing])
standardizeMissing(t,[datetime(2018,8,8) missing])
fillmissing(a,'constant',0) %变量中缺失值替换成参数,'constant'和0表示把缺失值替换为常数0
fillmissing(s,'constant',"fill")
fillmissing(t,'constant',datetime(2019,9,9))
%% 缺失值的移位(排序)
sort(a,'MissingPlacement','last') %把变量a中的缺失值移位到最后
%% 缺失值的运算
max(a) %忽略nan求最大值
sin(a) %nan的sin值就是nan
sum(a) %求和返回nan值
sum(a,'omitnan') %忽略nan
sum(rmmissing(a)) %移除a中的缺失值1.43 类型识别
1.判断数据的类型和类别
例如数值型(整数、浮点数、实数、无穷数、有限数、nan等)、字符(串)型、结构数组、元胞数组、表、函数句柄等
2.认识函数
变量信息whos
类型class
无穷大isinf
非值isnan
数值型isnumeric
实数isreal
有限值isfinite
综合判断isa
字符向量元胞数组iscellstr
3.简单总结数据类型
Matlab的基本类型(16个)
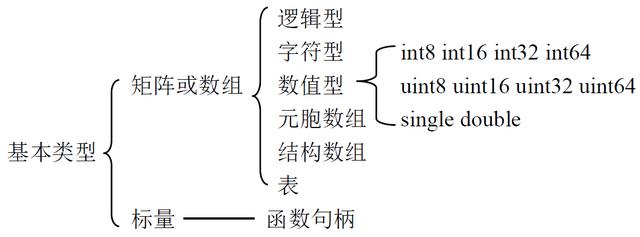
Matlab基本数据类型
4.实例演示
%1_43
%freexyn
x=1
whos x
class(x)
isnan(x)
isnan(nan)
isinf(x)
isinf(1e309)
isnumeric(x)
isnumeric('a')
isreal(x)
isreal(1+2i)
isfinite(x)
isfinite(1e309)
isa(x,'numeric') %判断数值型
isa(x,'integer') %判断整数
isa(int16(1),'integer') %判断int16(1)是否为整数
isa(x,'int8') %判断x是否为8位整型
isa(int8(1),'int8')
isa(x,'float') %判断浮点型
isa(x,'double') %判断双精度浮点型
isa(x,'single') %判断单精度浮点型
isa(x,'logical') %判断逻辑型
isa(true,'logical')
isa(x,'char') %判断字符型
isa('a','char')
isa(x,'string') %判断字符串型
isa('a','string')
isa("b",'string')
isa(x,'struct') %判断结构数组
isa(x,'table') %判断表数组
isa(x,'cell') %判断元胞数组
isa(x,'function_handle') %判断函数句柄
isa(x,'datetime') %判断日期时间型
isdatetime(x)
iscellstr({'11'}) %判断元胞数组是否由字符构成(是)
iscellstr({11}) %同上(不是,是双精度数值)(第四章结束,后接第五章,继续加油喔…)

如若转载,请注明出处:https://www.yiheng8.com/95293.html
 微信扫一扫
微信扫一扫 相关推荐
-
手机如何打开psd格式(手机编辑psd格式文件)
大家好,我是小草技术分享的小白,今天给大家分享 “怎么用ps软件打开cdr格式的文件?” 在平时图片设计制作中,会用到各种图片设计制作软件,根据需要有时得把图片文件在各个软件中打开…
-
抖音怎么提取视频声音,抖音怎么提取视频声音做铃声?
抖音怎么提取视频声音,抖音怎么提取视频声音做铃声? 有时候在观看视频时,会听到一段令人触动的旁白,比如罗翔老师所说的"法外狂徒张三",会让人想将这段话保存下来,配上…
-
美国牧场的小生活txt下载 下书网(美国牧场的小生活txt无错精校版)
美国旷日持久的新冠肺炎疫情,给该国农业和农场主生产、生活都带来了前所未有的冲击与挑战 。 在疫情常态化下,他们是怎样应对农业生产、生活,给我国农业特别是粮食主产区农民春备耕生产及生…
-
公司电脑监控文件拷贝记录 知乎查不到(公司电脑监控文件拷贝记录 知乎能看到吗)
现在无论是刚成立的公司还是正在稳步发展的公司,必不可少的都一定会给员工电脑部署好远程监控。员工在电脑上的一举一动不仅可以被实时监控,而且操作记录、浏览记录、文件行为记录和即时通讯记…
-
利川市天然气收费价格(天然气收费价格文件批复过期没有新的文件,怎么认定)
最近,天然气价格又上涨了,而且不是一个城市,而是全国各地。因为我们国家的天然气,都是从俄罗斯进口过来的,而现在俄罗斯和乌克兰打起来了。俄罗斯要打仗了,军费增加了,肯定就要提高天然气…
-
微信小程序金山文档怎么以文件形式发送,微信小程序金山文档怎么以文件形式发送到钉钉?
需求分析作为学校的数据统计人员,如班主任老师,学校中层,或者某项工作的负责人,经常会收到通过微信转发过来的,要求许多人填写的,Excel格式的统计表格,但是,这样的以文件形式分享的…
-
r怎么读取txt数据(r语言写入txt)
将数据保存到 TXT 文本的操作非常简单,而且 TXT 文本几乎兼容任何平台,但是这有个缺点,那就是不利于检索。所以如果对检索和数据结构要求不高,追求方便第一的话,可以采用 TXT…
-
农门科举之赚钱考试养家txt百度云下载(农门科举之赚钱考试养家txt百度云盘搜搜)
1、《独宠丑夫》 标签:生子、情有独钟、种田文、爽文 字数:819582(完结) 视角:主攻 2、《农门科举之赚钱,考试,养家》 标签:生子、种田文、重生、科举 字数:869020…
-
python程序文件的扩展名,python程序文件的扩展名主要有哪两种?
相信我,看完这篇文章,你的Python也会变得能歌善舞。 一般情况下,python程序都是静默运行的,也就是说,除非你紧紧盯着界面,否则你不知道你的程序是什么时候运行结束的。 《硅…
-
打印机可以把纸质文件扫描成电子版(纸质文件用打印机怎么扫描成电子版)
华为手机秒变移动“扫描仪”,想要PDF文件就是这么简单 大家好,欢迎回到办公半点功夫。科技飞速发展的今天,智能办公已成常态,手机上看文件,修改资料,编辑文档,传送文件已经是很平常的…