文章目录
私信小编01即可获取大量Python学习资源
前言
就在前几天一个大一学妹打破了我繁忙的生活,我纳闷了,直接问她啥事啊(老直男了)

原来是找我帮个忙,作为好学长那肯定得助人为乐啊…
话不多说,进入正题
一.需求分析
根据学妹的描述来看,就只是想要一个能识别图片文字的程序,那就不管啥排版了,直接依次识别算了,主要是忙…那我直接用百度的ocr就行了,半小时搞定它!
二.代码实现
1.百度文字识别
文字识别官方入口
https://ai.baidu.com/tech/ocr/general
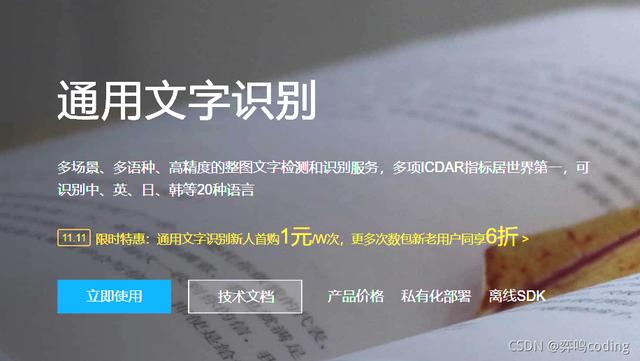
点击立即使用,我们就白嫖吧,反正一个月也用不到1000次
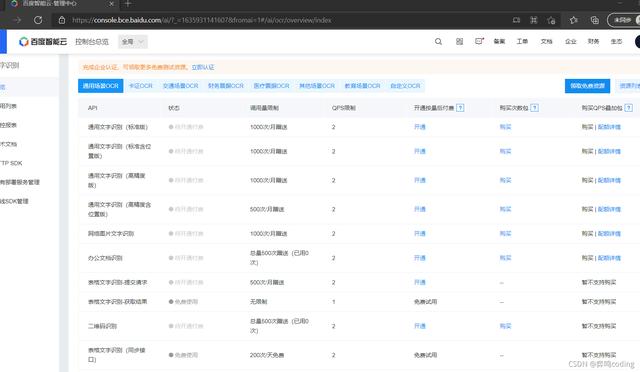
创建应用,输入应用名称,这个随意哈,然后选一个文字识别-免费的,有钱的话当我没说。
下图创建成功。
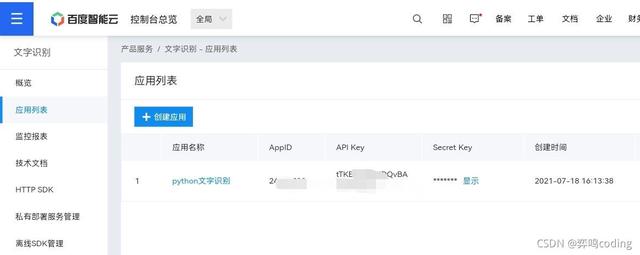
一会API Key和Secret Key是要使用的。
2.查看文档获取access_token
接下来就要去看看文档了,看是怎么使用的
https://ai.baidu.com/ai-doc/OCR/1k3h7y3db
不会看文档的小伙伴,我直接就讲我需要的东西了,其余的大家自己学着看吧。
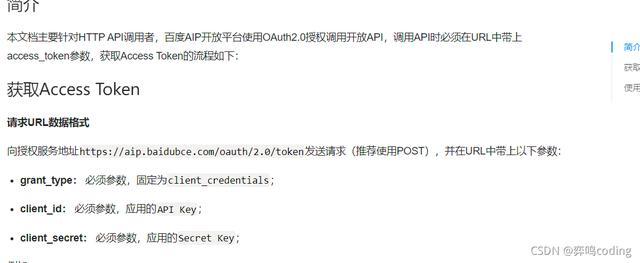
从文档来看,我们首先要获取一个东西——access_token
官网代码
# encoding:utf-8
import requests
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【官网获取的AK】&client_secret=【官网获取的SK】'
response = requests.get(host)
if response:
print(response.json())
我的代码
import requests
def access_token():
url = 'https://aip.baidubce.com/oauth/2.0/token'
token_ = {
'grant_type': 'client_credentials',
# API Key
'client_id': '官网获取的AK',
# ecret Key
'client_secret': '官网获取的SK'
}
res = requests.post(url, data=token_)
res = res.json()
print(res)
access_token = res['access_token']
print(access_token)
return access_token
if __name__ == '__main__':
access_token()
官网说推荐使用post,那我们就用post,但是官方代码是用的get这种方法,其实结果都一样,都能得到需要的数据。只不过官方的代码还需要一步提取出access_token。
access_token = response.json()['access_token']
然后就能得到access_token了。

如果在这个过程中遇到错误,文档也有,而且会比我讲的详细,所以遇到问题的话可以先看文档,实在不行可以问我。
获取access_token的函数
def access_token():
url = 'https://aip.baidubce.com/oauth/2.0/token'
token_ = {
'grant_type': 'client_credentials',
# API Key
'client_id': '自己获取',
# ecret Key
'client_secret': '自己获取'
}
res = requests.post(url, data=token_)
res = res.json()
print(res)
access_token = res['access_token']
print(access_token)
return access_token
当我们需要用时直接调用就行了。

根据文档的说明,我们就开始写读取图片的代码了
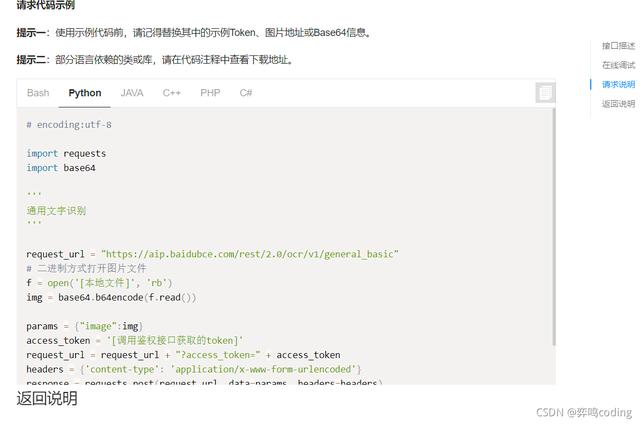
3.图片代码
def raed_pic(): url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate" request_url = url + "?access_token=" + access_token() f = open('6.jpg', 'rb') img = base64.b64encode(f.read()) # 参数看文档 params = {"image": img, "language_type": "CHN_ENG", "recognize_granularity": "small", } headers = {'content-type': 'application/x-www-form-urlencoded'} response = requests.post(request_url, data=params, headers=headers) # print(response) # res = response.json() # print(res) # 判断是否响应成功 if response: # 保存读出文字的文件,自动创建 file_name = "yiming6.txt" # 这个没说的了,就是写入操作 with open(file_name, 'w', encoding='utf-8') as f: for j in res: f.write(j["words"] + "\n")4.代码部分解读
从json分析来看我们只要提取当中的words_result里面的words

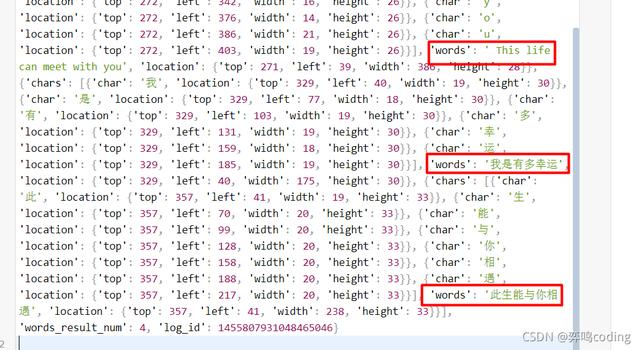
三.效果展示
效果如下:
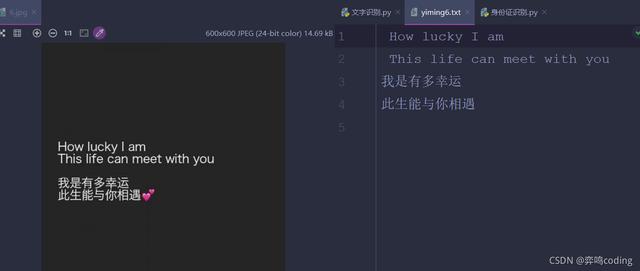
nice!当然可以写个循环然后直接遍历一个文件夹里面的所有图片,就可以得到每张图的文字了,再读取里面的文字放在同一个txt文件里面,有闲工夫的小伙伴可以试一试,我就不写了。最后也成功得到学妹的奶茶,就不上图片了,嘻嘻嘻~

如若转载,请注明出处:https://www.yiheng8.com/143623.html
 微信扫一扫
微信扫一扫 相关推荐
-
朋友圈文案生成软件,微信朋友圈文案制作?
神经网络伪原创认为这三种方法都可以免费使用。伪原创发生器。 如果大家看了这里也不知道如何免费使用的话,在下面问问编辑吧。 第一,有些人天生就有,但每个人都能在一定程度上改善自己的能…
-
广告的功能有什么(广告的功能都有什么)
在我们青春的记忆里,曾经在电视里听到过这样的几乎家喻户晓的广告词:“燕舞,燕舞,一片歌来一片情。”这是一个男生唱的广告词。是为当年的燕舞牌收录机做的广告。 这个广告,大概是在…
-
打鱼挣钱的游戏(哪个软件打鱼能赢钱的)
免责声明:本文旨在传递更多市场信息,不构成任何投资建议。文章仅代表作者观点,不代表火星财经官方立场。 小编:记得关注哦 来源:蜂巢财经News 在现象级网剧《鱿鱼游戏》热播时,以剧…
-
聊天赚钱的app软件平台有哪些可靠,聊天赚钱的app软件平台有哪些免费的?
一提到心理咨询,你会想到什么呢? 对很多人来说,他们脑中第一个浮现出的画面,是一个神情严肃的男人,一边做着笔记,一边时不时停下来对躺在躺椅上的那个人问:对此你感觉怎么样? 或者,你…
-
阅读软件一天能挣多少啊(每天可以免费阅读一小时的软件)
只要很多友友多互动,抄书打卡是可以赚钱的,虽然不高,但也是一种鼓励! 抄书赚钱 我一直喜欢吃路边摊的柠檬鸡爪、特别是上大学的时候经常跑去买来吃 夏天标配哦! 今天休息,特别想吃,于…
-
新手做自媒体用什么剪辑软件(做自媒体怎么拍摄和剪辑视频)
我也是新手哈,我只是说自己对自媒体的看法。 这几天我一直在思考自己该怎么玩头条号。 做自媒体第一步就是账号的定位。 说实话这一步我很纠结。 自媒体定位这一块我在网上找过资料。 尤其…
-
百度ai开放平台通用文字识别官网(百度ai开放平台通用文字识别js)
编辑导语:目前,AI是新的互联网潮流。而做好AI开发平台,一个关键因素是,做好数据管理。本篇文章中,作者从功能服务数据管理和业务数据管理两方面,分析了如何做好数据管理。感兴趣的小伙…
-
下载直播加加软件安全吗,下载直播加加软件安全吗是真的吗?
【新米行业研究报告-数策全行业调研报告】 专注于洞察全行业发展研究,关注我,带您前瞻各大行业未来趋势! 下文为报告部分内容,完整报告请关注并私信添加客服下载 一、MCN 对直播电商…
-
隐蔽即时聊天软件(即时聊天软件开发公司)
想了解上一版的朋友们可查看https://www.toutiao.com/article/7107142379966038566/?log_from=24a47651143ca_1…
-
b2b_推广平台,b2b网站推广软件?
文/两又同齐 两又同齐之佳不断分享,不断交流,不断进步,这里有英语/外贸/亲子教育/生活感悟以及一地鸡毛的琐碎自留地211篇原创内容 公众号:两又同齐之佳 每当我们接触到一个新的行…