

由于之前主要研究现代信号处理,对自然语言处理NLP不太了解,所以这篇文章诸位权当看个乐子。
福尔摩斯就不介绍了,大家都懂的,因此直接进入正题。本文使用Latent Dirichlet Allocation(LDA)主题模型分析福尔摩斯的原著小说和短篇小说中的文本。 LDA 是自然语言处理中的生成统计模型,可以发现文档中的潜在主题并推断主题中的单词概率,本文分为2个部分。在第1部分中,仅涉及福尔摩斯的原创作品。 2个数据集的总词数分别为203936个和454214,一共处理和分析了 658,150 个单词。福尔摩斯原著小说中共发现了4个主题,分别是“sir, holmes, think, case, watson“(“福尔摩斯与华生—友谊与主角”),“say, come, know, well, man”(“谜团和解谜”),“时间,小,房间,方式,发现”(“困难(例如时间和空间限制)”)和“人,得到,拿,问,做"(“案例的属性”)。在第 2 部分中,使用 3 部经典小说(简·奥斯汀的《理智与情感》、艾米莉·勃朗特的《呼啸山庄》和夏洛特·勃朗特的《简爱》)与福尔摩斯的短篇故事集来训练另一个 LDA 模型。第2部分新增的3部经典小说(《理智与情感》、《呼啸山庄》和《简爱》)分别为186302字、116537字和119580字,合计422419字。
首先开始第一部分,从第1组小说中加载和提取文本数据
data = readtable("SH_novels.csv",TextType="string");
head(data)
textData = data.Text;textData(1:4)
准备用于分析的文本数据
定义停用词列表
customStopWords = [stopWords "down" "upon" "back" "though" "away"];
reshape(customStopWords,[46 5])
然后进行处理
documents = preprocessText(textData);
documents(1:4)
创建词袋模型
bag = bagOfWords(documents)
词袋模型中删除总共出现不超过2次的词,并从词袋模型中删除任何不包含单词的文档。
bag = removeInfrequentWords(bag,2);
bag = removeEmptyDocuments(bag)
列出第一组小说中排名靠前的单词的频率
找出模型中排名前 20 的单词
k = 20;
T = topkwords(bag,k)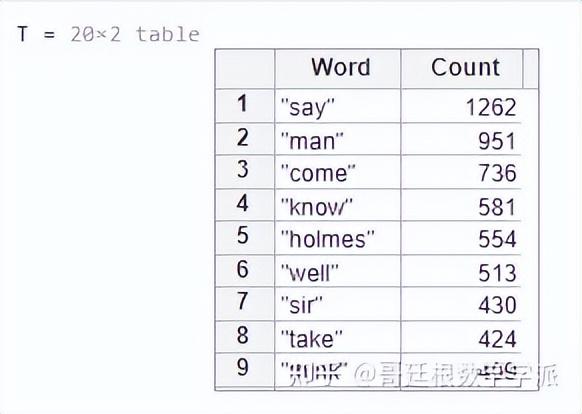
选择 LDA 模型的主题数量
随机留出 25% 的文档进行验证
numDocuments = numel(documents)
cvp = cvpartition(numDocuments,'HoldOut',0.25);
documentsTrain = documents(cvp.training);
documentsValidation = documents(cvp.test);从训练文档创建一个词袋模型,删除总共不超过两次的单词,删除任何不包含单词的文档
bagTrain = bagOfWords(documentsTrain);
bagTrain = removeInfrequentWords(bagTrain,2);
bagTrain = removeEmptyDocuments(bagTrain);选择与其他数量的主题相比最小化perplexity的主题
for i = 1:numel(numTopicsRange)
numTopicsTrain = numTopicsRange(i);
mdl = fitlda(bagTrain,numTopicsTrain, ...
'Solver','savb', ...
'Verbose',0);
[~,validationPerplexity(i)] = logp(mdl,documentsValidation);
timeElapsed(i) = mdl.FitInfo.History.TimeSinceStart(end);
end显示图中每个主题数量的perplexity和时间
figure
yyaxis left
plot(numTopicsRange,validationPerplexity,'+-')
ylabel("Validation Perplexity")
yyaxis right
plot(numTopicsRange,timeElapsed,'o-')
ylabel("Time Elapsed (s)")
legend(["Validation Perplexity" "Time Elapsed (s)"],'Location','southeast')
xlabel("Number of Topics")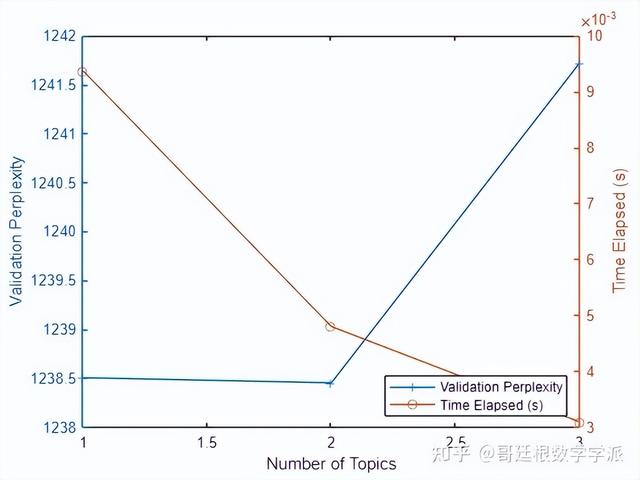
上图表明,拟合具有 3 个主题的模型效果还是不错的
LDA 模型拟合
尽管在上面的方法中发现这组文档的最佳主题数是 3,但在运行期间发现,拟合具有 4 个主题的 LDA 模型所需的时间也不多
rng("default")
numTopics = 4;
mdl = fitlda(bag,numTopics,Verbose=0);使用Word Clouds可视化主题

列出第一组小说中每个主题的 5 个热门词
k = 5;
for topicIdx = 1:numTopics
"Topic "+ topicIdx + " in Novels:"
tbl = topkwords(mdl,k,topicIdx)
topWords(topicIdx) = join(tbl.Word,", ");
endtbl = 5×2 table
|
Word |
Score |
|
|
1 |
"sir" |
0.0227 |
|
2 |
"holmes" |
0.0134 |
|
3 |
"think" |
0.0109 |
|
4 |
"case" |
0.0105 |
|
5 |
"watson" |
0.0104 |
tbl = 5×2 table
|
Word |
Score |
|
|
1 |
"say" |
0.0453 |
|
2 |
"come" |
0.0313 |
|
3 |
"know" |
0.0198 |
|
4 |
"well" |
0.0174 |
|
5 |
"man" |
0.0152 |
tbl = 5×2 table
|
Word |
Score |
|
|
1 |
"time" |
0.0185 |
|
2 |
"little" |
0.0147 |
|
3 |
"room" |
0.0120 |
|
4 |
"way" |
0.0116 |
|
5 |
"find" |
0.0115 |
tbl = 5×2 table
|
Word |
Score |
|
|
1 |
"man" |
0.0301 |
|
2 |
"get" |
0.0159 |
|
3 |
"take" |
0.0143 |
|
4 |
"ask" |
0.0137 |
|
5 |
"make" |
0.0127 |
查看第一组小说的主题概率
figure
bar(mdl.CorpusTopicProbabilities)
xlabel("Topic")
xticklabels(topWords);
ylabel("Probability")
title("Document Topic Probabilities in Novels")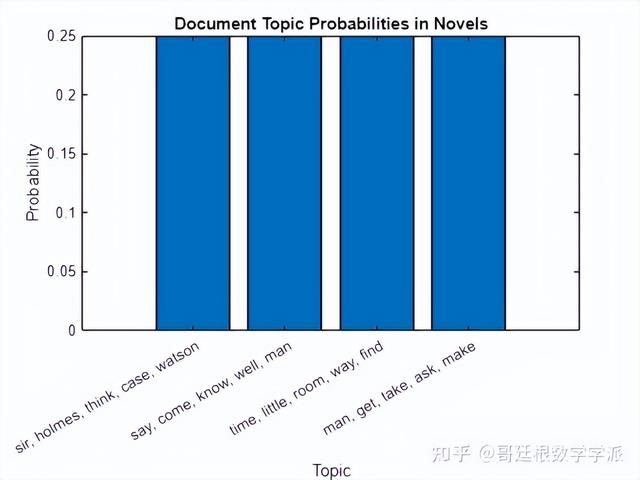
figurebarh(mdl.DocumentTopicProbabilities,"stacked")xlim([0 1])title("Topic Mixtures in Novels")xlabel("Topic Probability")yticklabels(data.Title)legend(topWords, ... Location="southoutside", ... NumColumns=1)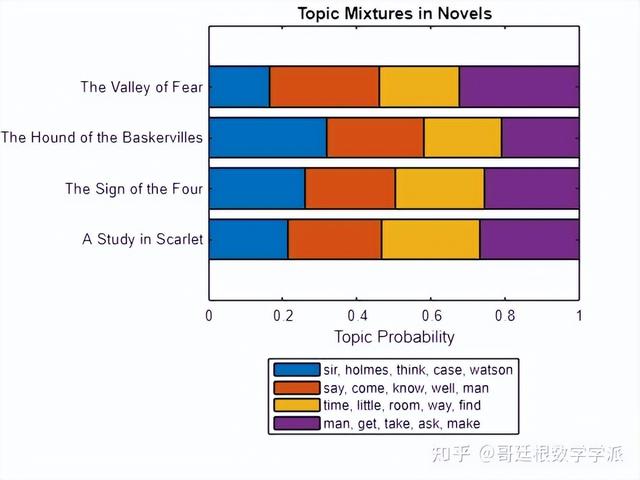
使用分组条形图可视化多个主题的组合
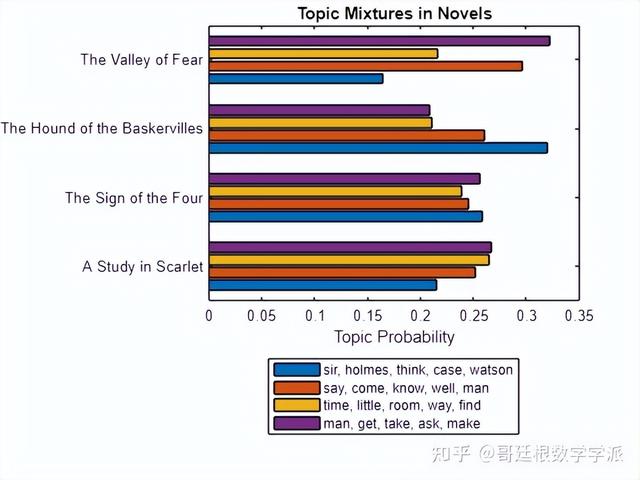
未完待续

如若转载,请注明出处:https://www.yiheng8.com/96790.html
 微信扫一扫
微信扫一扫 相关推荐
-
开店选址大数据分析软件(店铺选址分析软件)
“熊猫盘盘麻辣烫”隶属于长沙季布一诺餐饮管理有限公司,品牌主打新式麻辣烫、国潮麻辣烫、盘盘麻辣烫,以国民喜爱的国宝“熊猫”作为品牌命名,熊猫盼盼,熊猫盘盘由此而来。品牌差异化则是以…
-
抖音有多少用户2022官方数据(抖音有多少用户2021官方数据)
疫情之后,信息传播步入了一个全新的时代,短视频行业迎来了巨大的风口,其中抖音作为头部短视频平台,用户快速增量,从而带动平台丰富的商业形态,衍生出了多种模式的商品呈现。 品牌商家纷纷…
-
渣女星座排名 大数据(十大渣女星座排名)
点上面的名字就可以关注啦~ (温馨提示:你遇到过这样的渣女么!) ? 上周五推送的《520小心!星盘里的渣男配置!》得到了很多小伙伴的共鸣,《星盘里的渣女配置》赶紧安排上了,依旧是…
-
客户画像,客户特征分析?
乔布斯说过: 你需要比用户自己更了解他们,以至于在他们自己还没有意识到之前,你就已经了解到他们最需要的是什么。 随着存量经济时代和数字化浪潮的到来,"数字化变革"、…
-
销售数据统计分析报告ppt,销售数据分析报表模板excel?
订进存销,实际上就是指订货、采购入库、销售以及库存,但凡是要做服装零售数据化运营的都躲不过订进存销数据分析。问题在于这个订进存销分析报表该怎么做才能达到数据直观易懂的效果?BI工具…
-
免费抖音数据查询平台下载,免费抖音数据查询平台官网?
技术和业务是一个互构的关系,互相折腾,制造“麻烦”,共同成长。 7月20日,火山引擎原动力大会在京举办,字节跳动副总裁杨震原以抖音电商为例,分享了火山引擎是如何支持公司内部业务做好…
-
微信无响应怎么恢复正常,修复微信无响应的方法?
微信是一款国民级应用,然而许多用户在使用过程中会遇到闪退、打不开等问题。自行尝试解决时,可能会因错误操作导致重要聊天记录和数据丢失。在微信出现闪退或打不开的情况时,正确的自救措施是…
-
淘宝大数据分析报告文献(淘宝大数据分析报告准吗)
hello,大家好,我是大白,很高兴和大家分享阿里的 onedata 体系方法论。 前言 onedata体系方法论最早发起于阿里,随着数据时代的全面到来,数据中台产品的完善,很多公…
-
转转电商怎么做,二手电商运营策略?
一、背景 1.1 什么是精细化运营? 1.2 为什么要做? 二、C2B视角下的精细化运营 2.1 模块划分 三、系统设计 3.1 任务 3.2计划 3.3 遇到的难点 四、总结 一…
-
数据分析跟大数据平台,数据分析跟大数据平台的区别?
数据分析与大数据平台 —— 区别与联系 数据分析和大数据平台是如今信息时代的两个炙手可热的领域。虽然它们都与数据相关,但它们之间存在着一些关键的区别和联系。本文将深入探讨数据分析和…