

国际计算机视觉与模式识别会议(CVPR)是IEEE一年一度的学术性会议,是计算机视觉和模式识别领域的顶级会议。根据最新2021谷歌学术指标,CVPR在所有学术期刊和会议影响力排名中位居第4,仅次于Nature,NEJM和Science。会议有着较为严苛的录用标准,整体的录取率通常浮动于20%至30%,录取论文代表了计算机视觉领域最新的科技水平以及未来发展潮流。
近日,CVPR 2022官方公布了接收论文列表,本届大会大约 2067 篇论文被接收,其中京东探索研究院共34篇论文被CVPR收录,论文涵盖包括目标检测与识别、表征学习、知识蒸馏、图像生成、文本语义识别等领域。以下为京东探索研究院本次入选论文的亮点介绍:
01
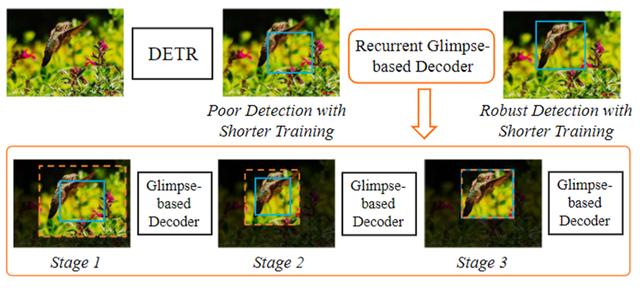
Recurrent Glimpse-based Decoder for Detection with Transformer
利用递归“瞥视”解码器
优化基于Transformer的目标检测算法
近期,基于Transformer的目标检测算法得到了大量关注。这一类算法通过建模全局视觉信息,能直接输出图片中出现物体的详细位置和类别信息。和传统目标检测算法不同,此类算法避免了额外的后处理过程,能高效高质量地进行目标检测。然而,此类算法往往需要极长的训练周期来优化模型参数并确保其能正确地关注物体区域。这一缺点极大地阻碍了相关领域的发展。尽管一些近期的工作指出优化特征表示或是改进模型结构能一定程度上缓解这一问题,我们发现有关可能包含物体的兴趣区域(region-of-interest)信息能直接、简单、有效地帮助缩短需要的训练周期。依此,在本文中,我们提出了一个利用递归“瞥视”解码器的方法来利用兴趣区域信息,从而有效加速基于Transformer的目标检测算法。
具体来说,我们试图模仿人类的视觉感知过程并借助类似于“瞥视”的行为获取有关物体位置的大致信息,然后通过一个多阶段递归的处理过程,帮助模型逐渐地聚焦到正确的物体区域,从而较大程度上降低模型进行目标检测的难度,减少其所需的训练周期。在每一个阶段中,我们通过扩大物体兴趣区域并提取其中的视觉信息作为“瞥视”的实现,然后我们引入了一个视觉解码器以解释获取到的“瞥视”信息。我们基于视觉解码器的输出来产生本阶段的目标检测结果,这一结果之后被递归地送到下一阶段的处理过程中,进而产生改善的目标检测结果。
在大数据集实验中,我们的方法可以被证明能减少30%左右当前最先进模型所需的训练周期且不使得目标检测准确率下降。在使用相同训练周期的情况下,我们的方法也能进一步提升5%左右的检测准确率。这些结果证明了我们提出的方法在基于Transformer的目标检测算法上的高效性,同时也展示出了我们的方法代表了本领域发展的最前沿成果。
02
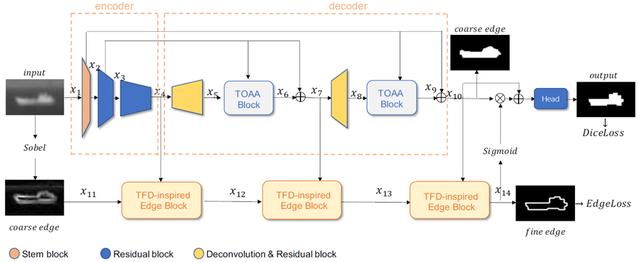
ISNet: Shape Matters for Infrared Small Target Detection
考虑形状的红外小目标检测网络
红外小目标检测(IRSTD)专门用于从模糊背景中提取小而微弱的目标,在交通管理和海上救援等场景中具有广泛的应用。由于低信噪比和低对比度,红外目标很容易淹没在具有各种噪声和杂波的背景中。如何检测红外目标的精确形状信息仍然非常具有挑战性。在本文中,我们提出了一种新颖的考虑形状的红外小目标检测网络ISNet,其中设计了受泰勒有限差分 (TFD) 启发的边缘模块和双向注意力聚合 (TOAA) 模块来解决这个问题。
具体而言,受TFD启发的边缘模块聚合并增强了来自不同层次丰富的边缘信息,以提高目标与背景之间的对比度,也为提取具有数学解释的形状信息奠定了基础。TOAA 块在行和列方向上通过注意力机制计算低层信息,并将其与高层信息融合,以捕获目标的形状特征并抑制噪声。此外,我们构建了一个新的基准,由 1000 个具有各种目标形状、不同目标大小和丰富杂波背景的真实图像组成,并带有准确的像素级注释,称为 IRSTD-1k。在公共数据集和 IRSTD-1k 上的实验证明了我们的方法优于具有代表性的最先进的 IRSTD 方法。数据集和代码将会公开。
03
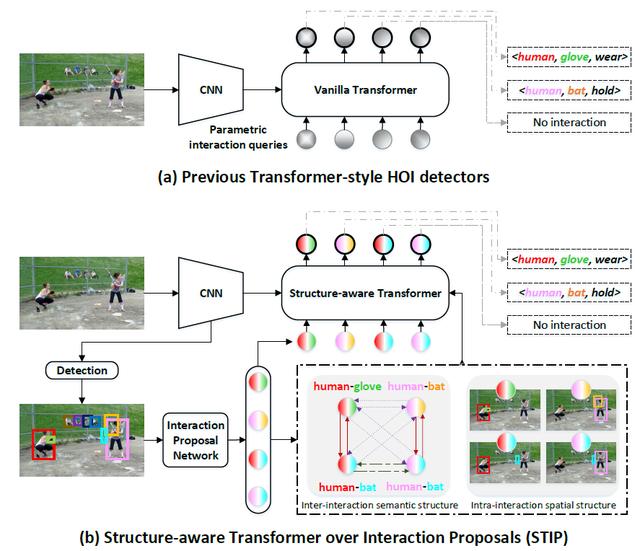
Exploring Structure-aware Transformer over Interaction Proposals for Human-Object Interaction Detection
基于结构感知Transformer的人物交互检测技术
最新的高性能人物交互(human-object interaction, HOI) 检测技术深受基于 Transformer 的目标检测器 (即 DETR) 的设计思想启发。大多数这类方法利用基础的 Transformer 架构,以单阶段的方式将一组可学习/参数化的交互查询 (queries) 直接映射为预测结果。然而,丰富的交互间和交互内结构信息并没有被充分利用。
在本工作中,我们设计了一种新型的基于 Transformer 的 HOI 检测器,称之为 STIP (Structure-aware Transformer over Interaction Proposals)。该设计将 HOI 集合预测过程分解为两个阶段,即首先生成交互提案 (proposals),然后通过结构敏感的 Transformer 将非参数化的交互提案映射为 HOI 预测。其中,结构敏感的 Transformer 通过额外编码交互间整体的语义结构,及单个交互内人与物的空间结构,从而增强 HOI 预测能力。我们在 V-COCO 和 HICO-DET 标准数据集进行了大量实验,验证了 STIP 的有效性,并获得了目前最佳的 HOI 检测性能。
04
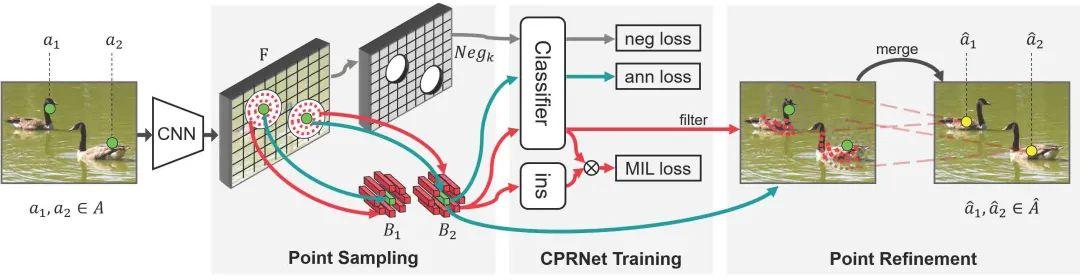
Object Localization under Single Coarse Point Supervision
单粗点监督下的目标定位
基于点的目标定位(POL)任务因能在低成本的数据标注下追求高性能的目标感知而越来越受到关注。然而,点标注表示目标不可避免地会因标注者等诸多因素产生不一致的现象从而引入语义方差的问题。但是现有的 POL 方法严重依赖于将标注点限制为准确的关键点标注来降低语义方差,而这种标注在多尺度多类别的场景往往很难清晰定义甚至是不存在的。在本文中,我们提出了一种使用粗点标注的 POL 方法,将监督信号从准确的关键点放松到随意标注的落在目标上的点。
为此,我们提出了一种粗点修正的(CPR)方法,据我们所知,这是首次从算法的角度减轻语义差异的尝试。CPR 构造点包、选择语义相关点并通过多实例学习 (MIL) 生成语义中心点。也就是说CPR 定义了一个弱监督的进化过程,保证了在粗点监督下依旧能够训练一个高性能的目标定位器。COCO、DOTA和我们提出的 SeaPerson 数据集上的实验结果都验证了 CPR 方法的有效性。数据集和代码将公布在https://GitHub.com/ucas-vg/TinyBenchmark 上。
05
Defensive Patches for Robust Recognition in thePhysical World
基于防御性图像块的鲁棒的真实世界的识别方法
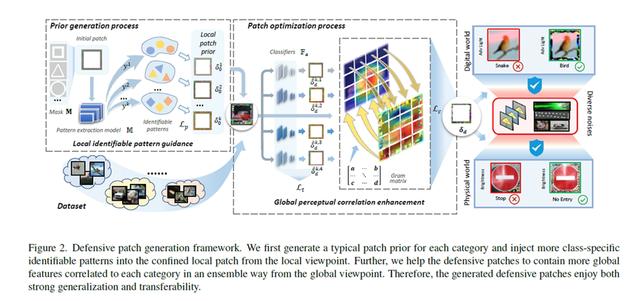
要在现实环境中运行,持续存在的噪声会影响深度学习系统的鲁棒性。基于数据的防御方式无需修改模型,而是通过对输入数据的增强来提高鲁棒性,由于其在实践中的可行性受到广泛关注。然而,基于数据的防御方式对各种噪声的泛化能力较弱,在多个模型之间的可移植性也较弱。为了使模型更好地利用这些特征来解决以上问题,由于鲁棒识别依赖于局部和全局特征,我们提出了一个防御图像块生成框架。
为了应对不同噪声,我们首先在有限的局部图像块中引入一类特定的可识别模式,使得防御图像块能够对特定的类保留更多的可识别特征,从而使模型在噪声下更好地识别。对于跨多个模型的可移植性,我们引导防御图像块捕捉类内更多的全局特征的关联,从而激活模型共享的全局感知,以便于更好地在模型间进行传递。我们的防御性图像块简单地附着在目标物体周围,在实际应用中表现出了极大的鲁棒性。广泛的实验表明,我们的防御性图像块的表现远远优于以往的方法。
06
DearKD: Data-Efficient Early Knowledge Distillation for Vision Transformers
基于早期知识蒸馏的
低数据依赖视觉Transformer
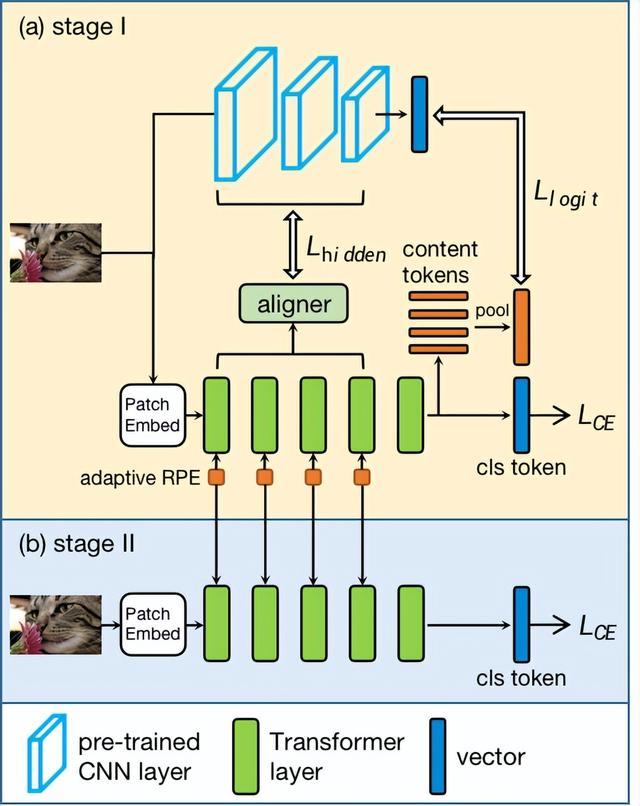
Transformer在视觉领域取得了巨大进展,然而却需要巨大的数据量,因此我们针对视觉Transformer提出了一种早期知识蒸馏框架——DearKD,来提升其在不同数据量下的性能,降低对数据量的敏感度。DearKD包含两个阶段,在第一阶段我们通过蒸馏卷积网络隐藏层与输出层的知识使得Transformer学到卷积网络的归纳偏置降低网络的数据依赖性,在第二阶段我们让网络学习自身固有的归纳偏置以提升网络的最终性能。
此外,DearKD还可以被应用在极端的无数据场景下,在这个场景下,我们提出了边界保持的多样性损失函数以提升生成样本的多样性的同时保证样本是真实性,使得样本更贴近真实数据。我们在ImageNet全部与部分数据、无数据以及下游任务上均取得了SOTA的性能。
07
Fine-tuning Global Model via Data-Free Knowledge Distillation for Non-IID Federated Learning
基于无数据知识蒸馏的
联邦学习全局模型微调方法
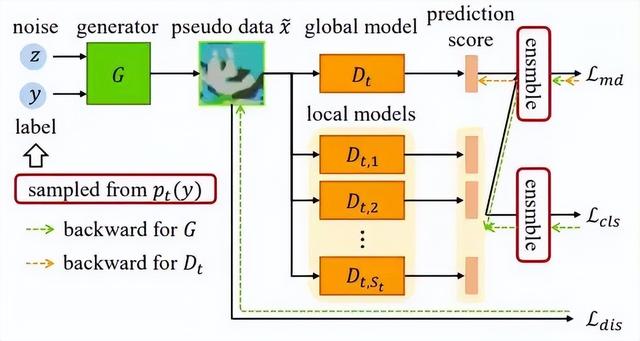
联邦学习是一种面向隐私保护的分布式学习范式。数据异构是联邦学习的主要挑战之一,它会导致联邦模型收敛速度变慢,性能下降。大多数现有方法仅通过限制客户端中的本地模型更新来解决数据异构性挑战,忽略了在服务器端进行模型聚合导致的性能下降。在本文中,我们提出了一种无数据知识蒸馏方法(FedFTG)来微调服务端上的全局模型,从而缓解直接进行模型聚合产生的性能下降问题。
具体地,FedFTG训练一个生成器来拟合局部模型的输入空间,并用它来将局部模型的知识迁移到全局模型。此外,我们提出了一种难样本挖掘方案,从而在整个训练过程中进行持续高效的知识蒸馏。更进一步,我们为每个客户端设计个性化的标签采样和知识蒸馏机制,从而隐含地减轻了客户之间的分布差异带来的影响,并最大限度地利用局部模型知识。大量实验表明,我们的FedFTG方法优于现有的联邦学习方法,并且可以作为一个全局模型增强模块提升FedAvg、FedProx、FedDyn和SCAFFOLD方法的性能。
08
Patch Slimming for Efficient Vision Transformers
高效视觉变形器的Patch裁剪
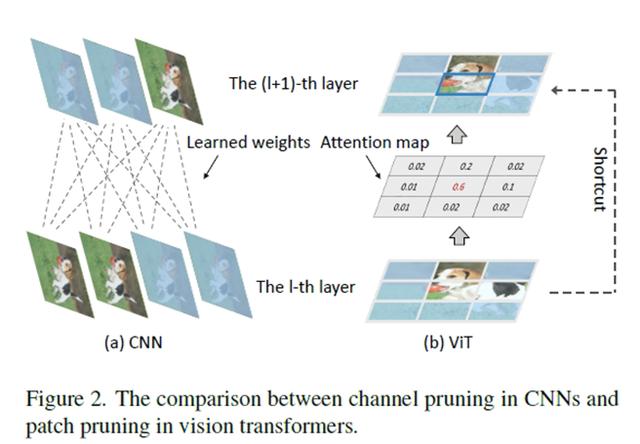
本文通过挖掘给定网络中冗余的计算来提升视觉Transformer的效率。最近, Transformer 架构已经证明了它能够在一系列计算机视觉任务上表现出出色的性能。然而,与卷积神经网络类似,视觉转换器的巨大计算成本仍然是一个严峻的问题。考虑到注意力机制会逐层聚合不同的图像块,我们提出了一种新颖的Patch裁剪算法,该方法可以在自上而地丢弃无用的图像块。
我们首先识别最后一层的有效图像块,然后使用它们来指导前一层图像块的选择过程。对于每一层中的每一个图像块最终输出特征的影响是相近的,影响较小的图像块将被删除。基于基准数据集的实验结果表明,本文提出的方法可以显著降低视觉Transformer的计算成本,而不会影响其性能。例如,ViT-Ti 模型的 FLOPs 可以减少 45% 以上,而 ImageNet 数据集上的 top-1 准确率仅下降 0.2%。
09
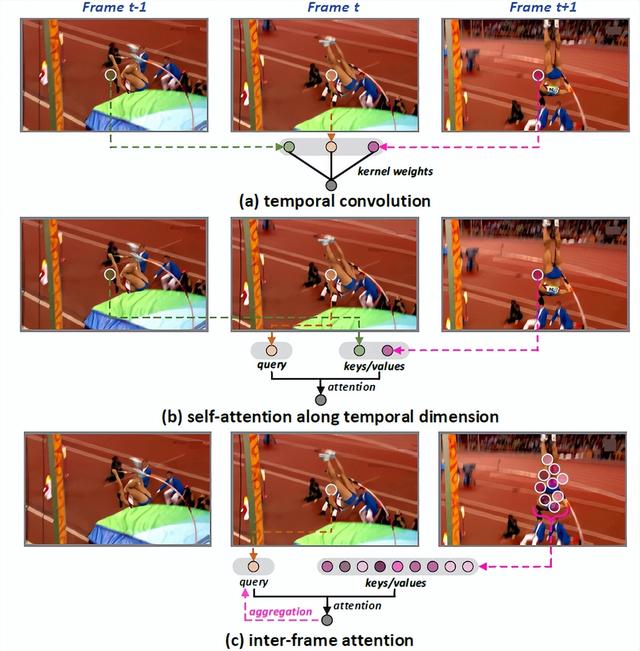
Stand-Alone Inter-Frame Attention in Video Models
独立帧间注意力视频建模技术
如何捕捉视频的动态信息是视频模型发展的关键。当下基于神经网络的视频模型主要通过两种方式进行动态建模。其一是利用时空三维卷积或者是分解的时空三维卷积(空域卷积+时域卷积)对动作进行捕捉,另一种是在时域上利用自注意力机制进行动态建模。但这两种技术都基于一个隐含的假设,那就是空间中的特征在连续帧之间能够很好地进行对准并完成聚合。但在现实情况中这种假设很难维持,特别是对于空间上形变比较大的动作而言。
所以,本工作从这点出发,设计一种可独立使用的可变形帧间注意力机制(Stand-alone Inter-Frame Attention (SIFA)),利用对帧间动作形变的预估帮助局部注意力的精确计算,从而提升模型对时空动作建模的性能。
具体而言,SIFA通过利用相邻两帧的差值信息估计位移来重塑形变自注意力机制。如果将当前帧的每一个位置作为查询项(query),那么下一帧的该位置的领域局部区域将被视作关键项/真值项(keys/values)。
其后,SIFA计算查询项和关键项的相似度,作为自注意力权重,用于真值项的时域聚合。我们进一步将SIFA模块插入到卷积网络和Transformer网络中,得到SIFA-Net和SIFA-Transformer结构。在四个动作识别数据集上的大量实验证明了SIFA-Net和SIFA-Transformer结构的优越性。更值得注意的是,SIFA-Transformer在Kinetics-400数据集上达到了83.1%的分类准确率。
10
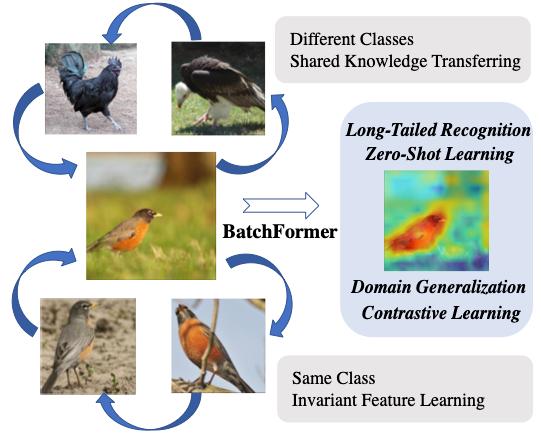
BatchFormer: Learning to Explore Sample Relationships for Robust Representation Learning
BatchFormer: 基于样本关系探索的表示学习
尽管深度神经网络取得了成功,但由于数据不平衡、零次分布和域偏移等数据稀缺性问题,深度表示学习仍然存在许多挑战。为了解决上述问题,人们设计了多种方法以普通的方式(即从输入或损失函数的角度)探索样本关系,没有用探索深度神经网络的内部结构来用于学习样本关系。受此启发,我们提出让深度神经网络本身能够从每个mini-batch 学习样本关系。
具体来说,我们提出了Batch Transformer 或 BatchFormer,然后将其应用于batch维度,以在训练期间隐式探索样本关系。通过这样做,BatchFormer可以实现不同样本的协作,例如,头类样本也可以有助于尾类的学习以进行长尾识别。此外,为了缩小训练和测试之间的差距,我们在训练期间共享有或没有 BatchFormer 的分类器,因此可以在测试期间将其删除。我们对十多个数据集进行了广泛的实验,所提出的方法在不同的数据稀缺应用上实现了显着改进,包括长尾识别、组合零样本学习、域泛化和对比学习。
11
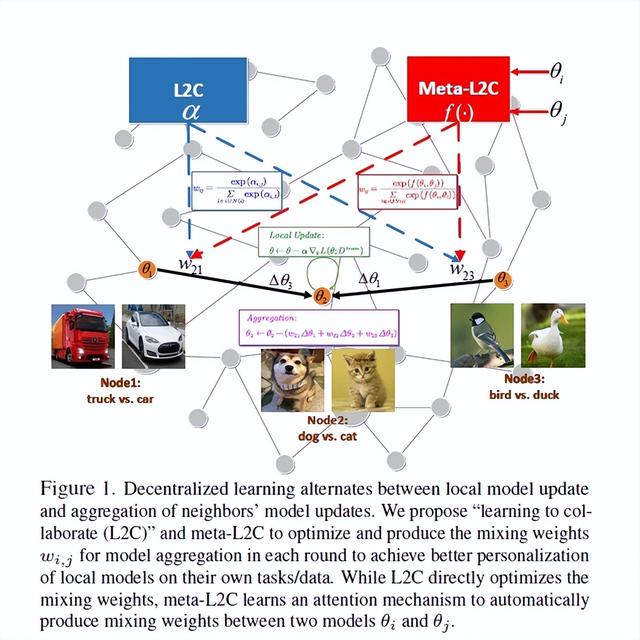
Learning to Collaborate in Decentralized Learning of Personalized Models
基于个性化模型的去中心化的协作学习
学习用户定制的计算机视觉任务的个性化模型具有挑战性,因为每个边缘设备上可用的私有数据和计算能力有限。去中心化学习可以利用分布在网络拓扑设备上的图像来训练全局模型,而不是为了针对不同的任务训练个性化模型或优化拓扑模型。此外,去中心化学习中用于聚合邻居梯度信息的混合权重对于个性化来说是次优的,因为它们不适应不同的节点/任务和学习阶段。本文通过动态更新每个节点任务的权重来提升每个节点的性能,同时学习稀疏拓扑来降低通信成本。
我们的第一种方法是“学习协作(L2C )”,它直接优化混合权重,以最小化每个节点在预定义的数据集上的局部验证损失。为了给新节点或任务生成混合权重,我们进一步提出了"meta-L2C ",通过比较两个节点的模型来更新,学习一种注意力机制来自动分配混合权重。我们在不同的图像分类基准和实验设置中评估这两种方法,对独立同分布(IID) /非IID去中心化学习和联邦学习的经典方法和近期方法进行了深入的比较,证明了我们的方法在确定节点邻居、学习稀疏拓扑,能以较低通信和计算代价产生更好的个性化模型。
12
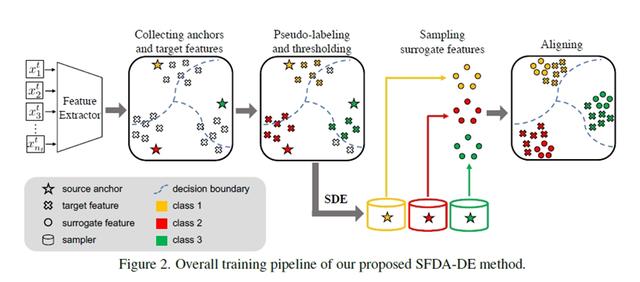
Source-Free Domain Adaptation via Distribution Estimation
通过分布估计进行无源域适应
域适应旨在将从带标签的源域学到的知识迁移到数据分布不同的无标注的目标域。然而,由于隐私保护政策,大多数现有方法所需的源域中的训练数据通常在实际应用中不可用。最近,无源域适应(SFDA)引起了广泛关注,它试图在不使用源数据的情况下解决域适应问题。在这项工作中,我们提出了一个名为 SFDA-DE 的新框架,通过源分布估计来解决 SFDA 任务。
首先,我们使用球形k-means聚类为目标数据生成鲁棒的伪标签,其初始类中心是预训练模型分类器学习的权重向量(锚点)。此外,我们建议通过利用目标数据和相应的锚点来估计源域的类条件特征分布。最后,我们从估计的分布中采样替代特征,并通过最小化对比适应损失函数来对齐两个域。大量实验表明,本文提出的方法优于需要大量源数据的传统域适应方法,在多个域适应基准上达到了最先进的性能。
13
Learning to Learn and Remember Super Long Multi-Domain Task Sequence
应用于记忆超长多领域任务序列的元学习
灾难性遗忘问题经常发生在输入数据为非平稳序列的情况中。此问题不仅没有被很好的探索过,并且它在序列化的领域(数据)的元学习问题(简称为“序列领域元学习”)中更加具有挑战性。在这项工作中,我们提出了一种简单而有效的学习方法,即元优化器,以缓解灾难性遗忘问题。首先,我们将元优化器应用在叫做“领域感知元学习”的简化的序列领域元学习设定中,其中领域标签和决策边界在学习过程中为已知的。
具体来说,我们动态的冻结网络,并考虑到在元学习训练中领域的自然特性,使用提出的元优化器对其进行优化。此外,我们将元优化器拓展到更加普适的序列领域元学习设定中,即领域不可知元学习,其中领域标签和决策边界在学习过程中为未知的。对此,本文提出了一种叫做领域偏移检测的技术,其在元优化器的辅助之下,能够捕捉到潜在的领域变化。除此之外,所提出的元优化器用途多样,能够轻松的集成到一些已有的元学习算法之中。最后,我们在一些具有挑战性的大规模基准数据集上进行了详实的实验,证明了本文方法在真实世界的图像及文字任务上的有效性,并大幅度超越了已有的高性能方法。
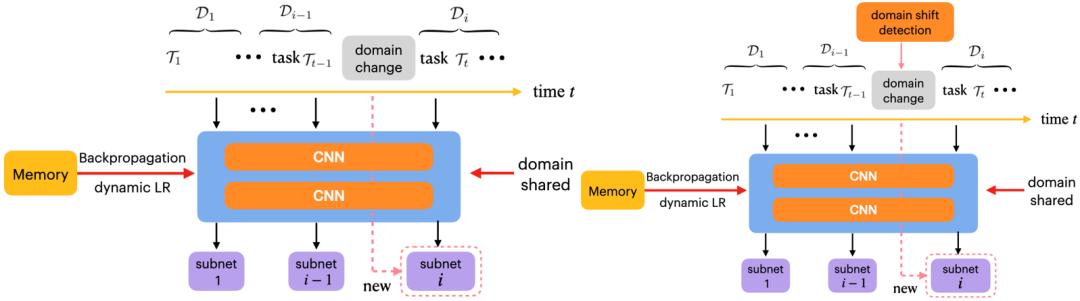
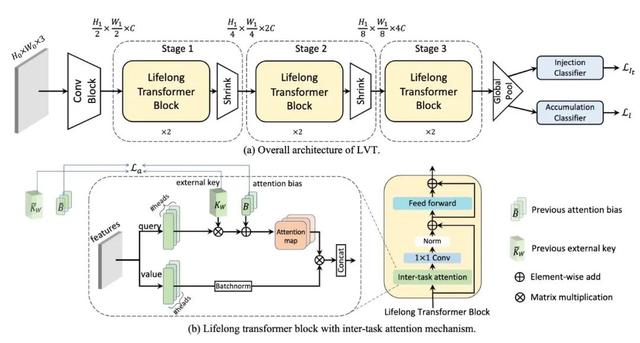
14
Continual Learning with Lifelong Vision Transformer
基于Lifelong Vision Transformer的连续学习
连续学习算法从不断到来的数据流中训练神经网络,以减轻灾难性遗忘。然而,现有的方法都是基于卷积神经网络 (CNN) 并为其设计的,这些方法并没有充分利用新出现的Vision Transformer的潜力。在本文中,我们提出了一种新颖的基于注意力的框架 Lifelong Vision Transformer (LVT),以在连续学习中实现更好的稳定性-可塑性权衡。
具体来说,LVT中提出了一种任务间注意力机制,它隐式地吸收了先前任务的信息,减缓了重要的注意力在先前任务和当前任务之间的漂移。LVT 设计了双分类器结构,独立注入新的表征以避免对先前知识的干扰,并均衡地积累新旧知识以提升整体性能。此外,我们还开发了一种基于置信度的缓存更新策略,以加深对先前任务的印象。广泛的实验结果表明,我们的方法在连续学习的基准数据集上以更少的参数实现了最先进的性能。
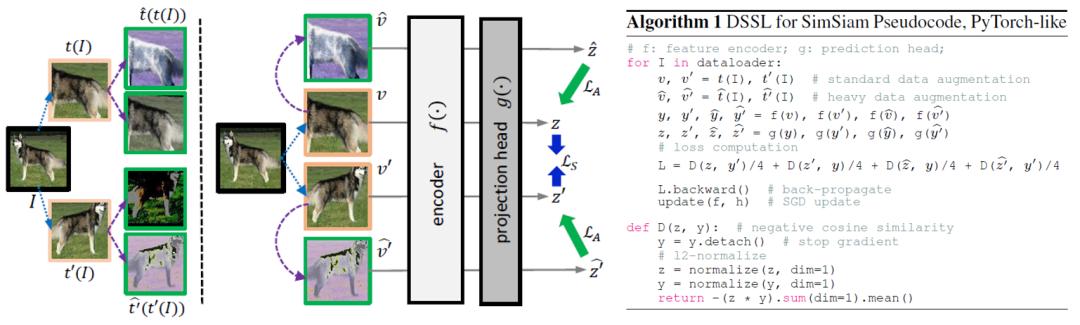
15
Directional Self-supervised Learning for Heavy Image Augmentations
面向强数据增广的有向自监督学习方法
尽管各类强数据增广策略被广泛应用于提升有监督特征学习任务的性能,但是只有少数经过筛选的轻增广策略有助于自监督图像特征表示学习。本研究旨提出了一种可以适配各类强数据增强策略的有向自监督学习范式(DSSL)。我们在弱数据增广策略的视图(SV)基础上引入强增广策略,生成与原始图片的差异程度较SV更大的视图(HV)。
传统的自监督学习方法最大化同一图片派生出的所有视图对之间的相似度,而DSSL将同一图片派生出的视图定义为偏序集合(SV-SV, SV←HV) ,按照视图之间的偏序关系构造非对称损失函数来优化模型训练。DSSL可以通过几行代码轻松实现,并且对于目前流行的自监督学习框架高度灵活,包括SimCLR、Sim-Siam、BYOL、MoCo V2和Barlow Twins。在 CIFAR 和 ImageNet上的大量实验结果表明,DSSL可以稳定地提升各类有监督学习框架的性能,并兼容更广泛的数据增广策略。
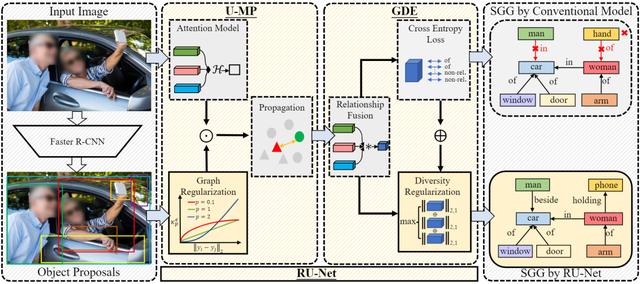
16
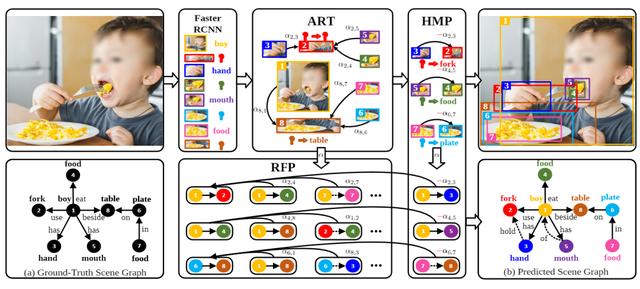
RU-Net: Regularized Unrolling Network for Scene Graph Generation
RU-Net:基于正则化展开的场景图生成
场景图生成(SGG)旨在检测图像中的物体并预测每对物体之间的关系。现有的 SGG 方法通常存在两个问题:1) 由于图神经网络的消息传递 (GMP) 模块对虚假(错误)的节点间联系比较敏感,导致物体表征变得模棱两可;2) 由于类别不均和标签缺失,导致关系预测的多样性降低。为了解决这两个问题,我们在文章中提出了一个正则化展开网络(RU-Net)。
首先,我们从unrolling算法的角度出发,研究了 GMP 与图拉普拉斯去噪 (GLD) 之间的关系,推导出GMP可以表述为 GLD 的求解器。基于这一证明,我们提出了一个基于unrolling的消息传递模块,并引入了一个基于p-范数的图正则化项来抑制节点之间的虚假连接。其次,我们提出了一个group(组)多样性增强模块,通过秩最大化来提升关系预测的多样性。大量实验表明,RU-Net 在各种设置和指标下都是有效的。除此之外,RU-Net 在三个流行的数据库:VG、VRD 和 OI 上达到了最高的性能。同时,代码将在 GitHub 上发布。
17
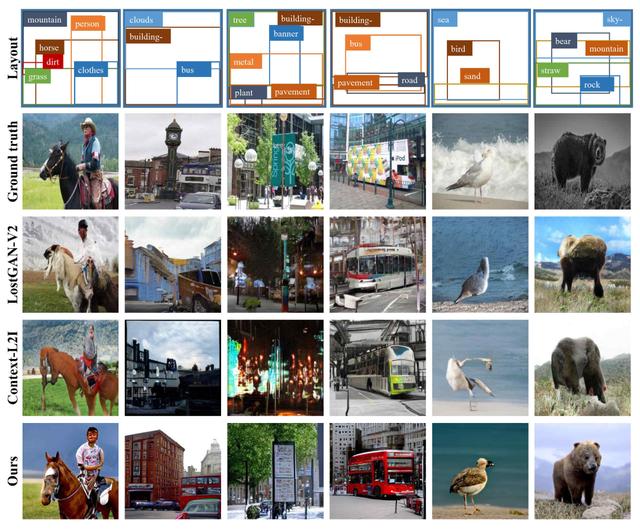
Modeling Image Composition for Complex Scene Generation
复杂场景生成的图像解构建模
本文提出了一种新的(few-shot)Layout-to-Image的图像生成方法,该方法通过对复杂场景中各个物体之间的关系、每个物体内部的结构以及局部纹理进行精确建模,从而实现了目前该任务上的最优结果。我们提出了一种新的模型,Transformer with Focal Attention (TwFA),用于探索被压缩成 Patch Token 的图像中 Object到Object、Object到Patch 以及 Patch到Patch 之间的依赖关系。
目前基于 CNN 和基于 Transformer 的生成模型分别在Pixel/Patch-Level和Object/Patch-Level存在建模纠缠的问题,与这些方法相比,所提出的 Focal Attention 仅关注具有空间相关性的 Token 来实现当前 Patch Token 的预测,从而在训练过程中消除歧义。此外,所提出的 TwFA 大大提高了训练期间的数据利用效率,因此基于预先训练好的TwFA,我们第一个提出了少样本复杂场景的生成策略。实验结果表明,TwFA无论是在定量指标还是定性比较都显著优于目前基于 CNN 和基于 Transformer 的方法。
18
HL-Net: Heterophily Learning Network for Scene Graph Generation
HL-Net: 基于异质性学习的场景图生成
场景图生成 (SGG) 旨在检测图像中的物体,并预测物体之间的关系。现有的场景图生成方法通常利用图神经网络 (GNN) 来获取对象/关系之间的上下文信息。然而,尽管它们是有效的,但当前的 SGG 方法只假设场景图是同质的,而忽略了异质性。因此,我们在文章中提出了一种新颖的异质性学习网络(HL-Net),从而全面探索场景图中对象/关系之间的同质性和异质性。HL-Net 包括以下内容:
1)基于自适应重加权的Transformer模块,通过自适应地整合来自不同图网络层的信息,从而更好地学习物体之间的同质性和异质性;
2)关系特征传递模块,通过考虑关系之间的异质性,有效地探索关系之间的联系,以细化关系表示;
3)基于异质感知的消息传递模块,通过进一步区分物体/关系之间的异质性和同质性,从而促进改进图中的消息传递。我们通过对Visual Genome (VG) 和Open Images (OI)两个公开数据集进行广泛的实验,结果证明了我们提出的 HL-Net 优于现有的方法。在VG 数据库上,HL-Net在场景图分类的任务上比第二好的方法性能高出2.1%;在 IO 数据集上的最终得分高出第二好的方法1.2%。同时,代码将在 GitHub 上发布。
19
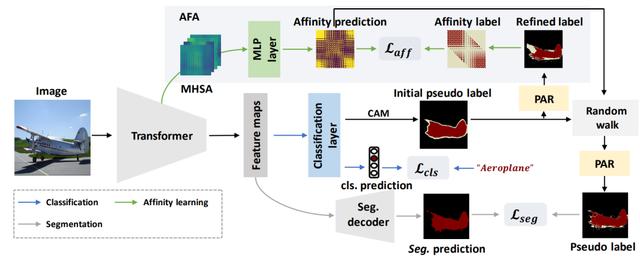
Learning Affinity from Attention: End-to-End Weakly-Supervised Semantic Segmentation with Transformers
从注意力中学习语义亲和关系:
基于Transformer的端到端弱监督语义分割
基于图像级标注的端到端弱监督语义分割是一项非常具有挑战性的任务。目前的方法主要基于卷积神经网络,无法准确建模全局信息,因此会导致初始伪标签的对象区域不完整。在本文中,为了解决该问题,我们引入了Transformer结构,它自然地整合了全局信息,从而能生成更完整的初始伪标签。
进一步的,受Transformer中的自注意力和语义关联之间的内在一致性的启发,我们提出了一个Affinity from Attention (AFA)模块来从Transformer中的多头自注意力矩阵中学习像素的语义关联。然后利用学习到的语义关联来细化初始伪标签。此外,为了有效地导出用于监督AFA模块的可靠标签,并确保伪标签的局部一致性,我们设计了一个像素自适应细化模块。该模块基于low-level图像外观信息来细化伪标签。我们在VOC和COCO数据集上进行了实验,取得了显著优于最近方法的效果。
20
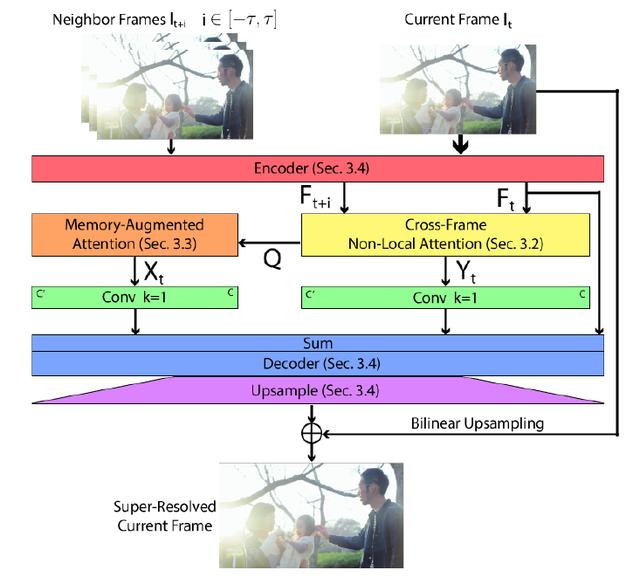
Memory-Augmented Non-Local Attention for Video Super-Resolution
基于记忆单元和全局注意力机制的视频超分辨率
本文提出了一种简单有效的从低分辨率视频恢复高保真和高分辨率视频的方法。已有方法主要利用时域相邻帧来辅助关键帧的超分辨率,但由于在空间对齐相邻视频帧难度较大,并且同为低分辨率的相邻视频帧可以提供的有用高频信息有限,现有视频超分辨率性能受到了限制。针对这个问题,我们提出了一种跨帧注意力机制,可以在不进行显式空间对齐相邻帧的情况下进行视频超分辨率,在包含较大运动的视频中展现出了出色的鲁棒性。
另外,为了获取输入低分辨率视频的之外的图像细节信息,并对运动视频中信息损失进行补偿,我们提出了一种全新的记忆增强机制,以在网络训练阶段记忆通用的视频图像信息,辅助测试过程中的视频超分辨率。经过在多个有挑战性的视频数据集进行大量的评估,与当前最先进的视频超分辨率方法相比,我们的方法不仅具有显著的性能提升,并且对不同类型的实际视频中有很好的通用性。
21
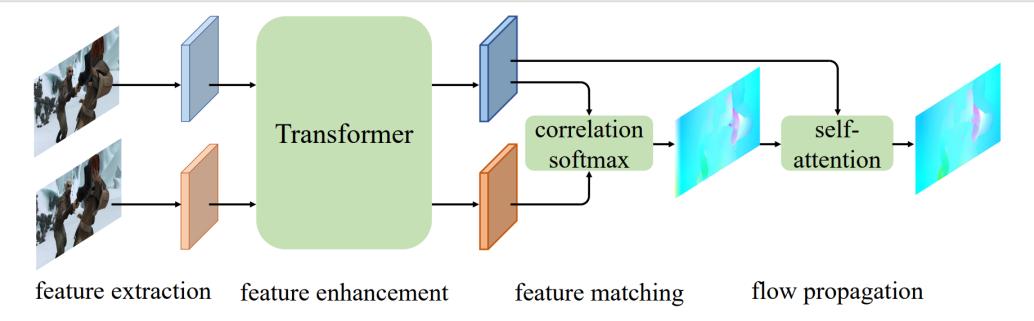
GMFlow: Learning Optical Flow via Global Matching
通过全局匹配学习光流
基于深度学习的光流估计一直被使用代价体和卷积的回归框架所主导。这种框架本质上局限于局部相关性,因此很难应对光流领域长期存在的大运动这一挑战。为缓解这一问题,当前的代表性算法 RAFT 通过大量序列的迭代精细化来不断提升其预测的效果,从而取得了出色的性能。但这种序列化的预测方式带来了线性增加的推理时间。为了实现高效高精度的光流估计,我们将光流重新定义为一个全局匹配问题从而彻底改造了主导的光流学习范式。
具体地,我们提出了一个 GMFlow 框架,它由三个主要部分组成:用于特征增强的 Transformer, 用于全局特征匹配的相关性和 softmax 层,以及一个用于光流传播的自注意力层。此外,我们介绍了一个在高分辨率复用 GMFlow 的精细化步骤来进一步提升性能。我们的新框架在具有相当挑战性的 Sintel 数据集上取得了超越 32 次迭代精细化的 RAFT 的性能,同时只采用一次精细化并且速度更快,为高效高精度光流估计提供了新的可能性。我们的代码和模型将会公开于:https://github.com/haofeixu/gmflow
论文:https://arxiv.org/abs/2111.13680
22
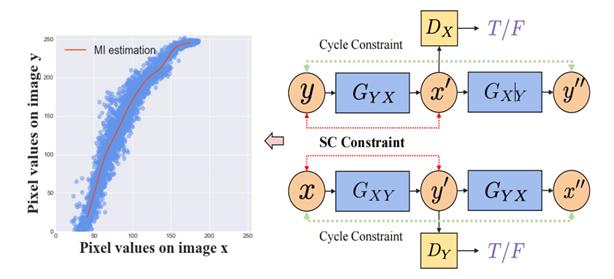
Alleviating Semantics Distortion in Unsupervised Low-Level Image-to-Image Translation via Structure Consistency Constraint
利用结构一致性约束减轻无监督低层次图像转换中的语义失真
无监督图像到图像(I2I)的翻译旨在学习一个域映射函数,该函数可以在没有配对数据的情况下保留输入图像的语义。然而,由于源域和目标域中的底层语义分布经常误匹配,当前基于分布匹配的方法在匹配分布时可能会扭曲语义,导致输入和翻译图像之间的不一致,这就是所谓的语义失真问题。本文专注于低层次的 I2I 翻译,其中图像的结构与其语义高度相关。
为了在没有配对监督的情况下减轻此类翻译任务中的语义失真,我们提出了一种新的 I2I 翻译约束——结构一致性约束 (SCC),通过减少翻译过程中颜色变换的随机性来提高图像结构的一致性。为了帮助更好地估计SCC和最大化SCC,我们提出了一种高效的互信息的近似表示,称为相对平方损失互信息 (relative Squared-loss Mutual Information,rSMI)。我们的 SCC 可以轻松整合到大多数现有的翻译模型中。在一系列关于低层次 I2I 翻译任务的定量和定性的实验中表明,使用 SCC 的翻译模型在几乎不增加额外计算和内存成本的情况下,显著优于原始模型。
23
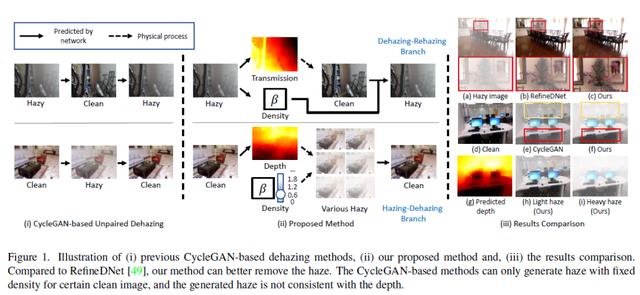
Self-augmented Unpaired Image Dehazing via Density and Depth Decomposition
基于密度和深度分解的自增强非成对图像去雾
为了克服在合成数据集上训练的去雾模型的过拟合问题,许多最近的方法试图使用非成对数据进行训练来提高模型的泛化能力。然而其中大多数方法仅仅简单地遵循CycleGAN的思路构建去雾循环和上雾循环,却忽略了现实世界中雾霾环境的物理特性,即雾霾对物体可见度的影响随深度和雾气密度而变化。在本文中,我们提出了一种自增强的图像去雾框架,称为D4(Dehazing via Decomposing transmission map into Density and Depth),用于图像去雾和雾气生成。
我们所提出的框架并非简单地估计透射图或清晰图像,而是聚焦于探索有雾图像和清晰图像中的散射系数和深度信息。通过估计的场景深度,我们的方法能够重新渲染具有不同厚度雾气的有雾图像,并用于训练去雾网络的数据增强。值得注意的是,整个训练过程仅依靠非成对的有雾图像和清晰图像,成功地从单个模糊图像中恢复了散射系数、深度图和清晰内容。综合实验表明,我们的方法在参数量和FLOP更少的情况下去雾效果优于最先进的非成对去雾方法。
24
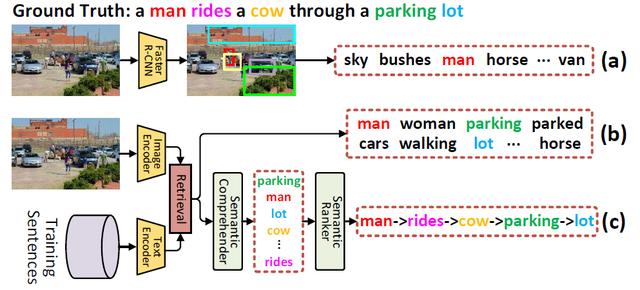
Comprehending and Ordering Semantics for Image Captioning
基于语义理解与排序的图像描述
理解图像中丰富的语义并将其按照语序进行排列对于生成视觉相关且语言连贯的描述至关重要。现有的图像描述方法大多依赖一个预训练的目标检测器或者分类器来挖掘图像中的视觉语义,而往往忽略了这些语义之间的语序关系。我们在论文中提出了一个基于Transformer结构的新方案,称为语义理解与排序网络(Comprehendingand Ordering Semantics Networks,COS-Net)。COS-Net新颖地将强化语义理解以及可学习语义排序过程集成到了一个统一网络中。
COS-Net先利用一个跨模态检索模型来为每一张图像检索相关的句子,然后这些句子中的词语构成初始的语义线索,然后利用一个全新的语义理解器过滤不相关的语义线索,同时推测图像缺失的相关语义词语并加入到语义线索。接着,语义线索中剩下的所有词语会被输入到一个语义排序器中,该排序器通过学习人类的语序习惯来为这些词语进行自动排序。最后,排序后的语义词语序列结合图像的视觉信息用于生成图像描述。COS-Net在COCO数据集上能够很明显地超过现有的前沿算法,在测试集上的CIDEr分数达到了141.1%。
25
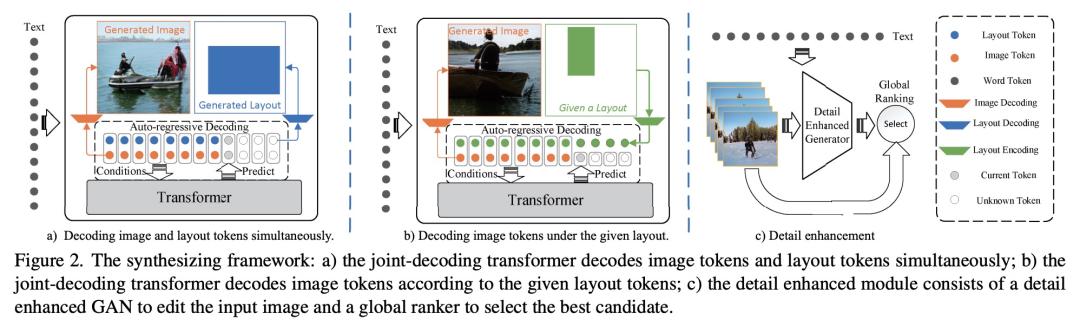
Text-to-Image Synthesis based on Object-Guided Joint-Decoding Transformer
面向对象引导联合解码Transformer的文本到图像合成
面向对象的文本到图像合成常常以两步方式生成自然语言描述的图像:首先使用文本生成场景布局信息,然后基于该布局和文本合成相应的图像。在该任务中,生成符合语言描述的结果都不是简单任务,并常会遇到处理过于复杂和错误传播等问题。此外,目前如CogView和DALL-E等先进方法没有考虑到场景布局相关信息,往往难以有效地细致控制场景的合成以生成符合用户偏好需求的图像。因此,基于Transformer结构,我们提出了一种对象引导的联合解码方法,能够同时生成符合语言描述的图像和相应的场景布局。
为了在Transformer中引入场景布局信息,我们构造了Layout-VQGAN来压缩类别形式的场景布局信息,以生成布局tokens并与图像tokens联合描述场景。此外,考虑到在VQ-GAN的压缩过程中可能会丢失图像细致细节特征及联合Transformer生成能力受资源限制等问题,我们构建了一种基于仿射组合模块的文本细节增强模型,以改善文本相关的图像生成细节。实验结果表明,我们的方法能够使用文本生成高质量图像,并且能够根据给定的场景布局信息生成相应的多样化图像。
26
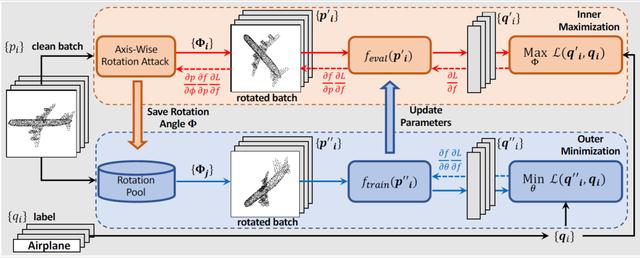
ART-Point: Improving Rotation Robustness of Point Cloud Classifiers via Adversarial Rotation
ART-Point:使用对抗旋转提升点云分类器的旋转鲁棒性
具有旋转鲁棒性的点云分类器的研究受到了三维深度学习社区的广泛关注。目前,大多数现有方法要么使用旋转不变描述符作为输入,要么尝试设计旋转等变网络。然而,由于这些方法对原始分类器或输入空间的修改,所生成的旋转稳健模型在干净对齐的数据集下的性能受损。在这项研究中,我们首次表明,点云分类器的旋转鲁棒性也可以在不影响模型结构的基础上,通过对抗训练获得,从而在旋转数据集和干净数据集上具有更好的性能。
具体来说,我们提出的名为 ART-Point 的框架将点云的旋转视为一种攻击,并通过寻找具有强攻击性的旋转样本,并在该样本上训练分类器以提高旋转鲁棒性。我们提供了一种轴向旋转攻击,它使用预训练模型的反向传播梯度来有效地找到强攻击性旋转。为了避免模型对攻击性输入的过拟合,我们构建了旋转池,利用样本间对抗性旋转的可转移性来增加训练数据的多样性。此外,我们提出了一种快速的一步优化,以有效地达到最终的稳健模型。实验表明,我们提出的旋转攻击在常见点云模型上取得了很高的成功率,同时ART-Point 可用于大多数现有分类器以提高旋转鲁棒性,同时在干净的数据集上显示出比最先进方法更好的性能。
27
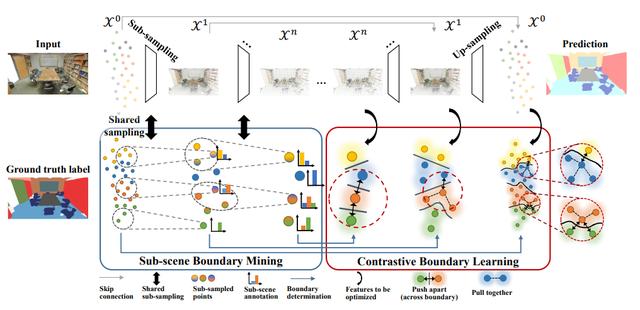
Contrastive Boundary Learning for Point Cloud Segmentation
基于对比边缘学习的点云分割
点云分割是理解3D环境的基础。然而,目前的三维点云分割方法对场景边缘的分割效果较差,影响了整体分割效果。本文主要研究场景边缘的分割问题。因此,我们首先探讨在场景边缘上评估分割性能的指标。为了解决在边缘上的性能不理想的问题,我们提出了一种新的对比边缘学习(Contrastive Boundary Learning)框架用于点云分割。
具体而言,提出的CBL通过在多个尺度上借助场景上下文对比点的表示,增强了跨边缘点之间的特征区分。通过在三种不同的基线方法上应用CBL,我们的实验表明,CBL能够不断地改进不同的基线,并帮助它们在边缘及整体上均实现了令人注目的性能。这些实验结果证明了该方法的有效性和边缘对三维点云分割的重要性。代码和模型将在https://github.com/LiyaoTang/contrastBoundary上开源。
28
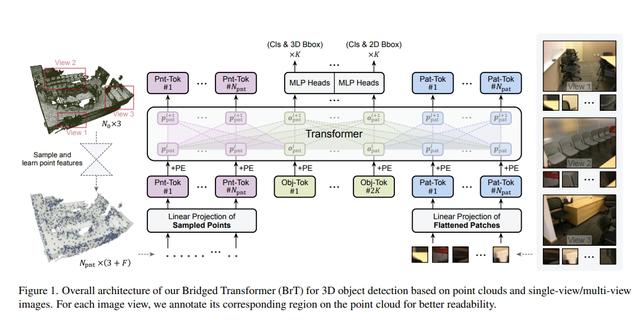
Bridged Transformer for Vision and Point Cloud 3D Object Detection
桥接图像-点云的多模态三维检测Transformer模型
三维检测是计算机视觉领域的重要研究课题,在传统的研究设置中常常基于三维点云进行学习。最近,在三维检测的研究中有一种利用多种来源输入数据的趋势,例如使用色彩图像来对点云进行补充。然而,由于二维和三维表示具有异构的几何结构,使得现成的神经网络模型难以被直接用于实现图像-点云融合。
为此,我们提出了桥接Transformer(BrT),一种用于三维检测的端到端架构。BrT是一种简单有效的方法,它可以同时从点云和图像中学习识别三维和二维物体的检测框。BrT的一个关键要素在于使用目标索引来桥接三维和二维特征,这将不同数据源的数据表示统一在一个Transformer中。我们采用了一种通过点到图像的投影实现特征聚合,进一步加强了模态之间的相关性。实验表明,在SUN RGB-D和ScanNetV2数据集上,BrT超过了已有的先进方法。
29
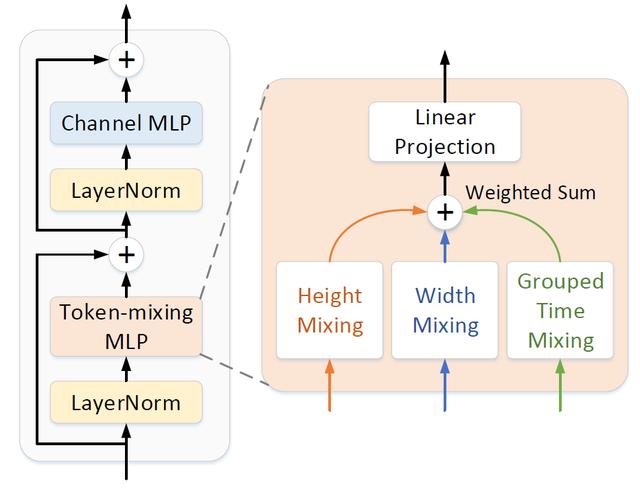
MLP-3D: A MLP-like 3D Architecture with Grouped Time Mixing
基于分组时域混合的三维多层感知机结构
目前基于自注意力机制或多层感知机的无卷积神经网络逐渐变得越来越流行,用以替代传统的卷积神经网络。然而由于视频数据的内容多样性与复杂性,简单地将这类新型神经网络应用在视频识别上并不能取得很好的效果。所以本工作针对视频分类提出了一种新的三维多层感知机结构。该结构包含多个多层感知机模块,其中每一个模块包括一个跨不同元素之间的多层感知机与一个对每个元素独立作用的多层感知机。通过引入分组时域混合操作,跨元素多层感知机被赋予了对时序序列进行建模的能力。
分组时域混合将不同元素根据时间分成不同的组合,并对每一组内的元素独立进行映射,从而降低操作的复杂度。更进一步地,不同种类的分组时域混合操作通过网络结构搜索的方式构成了最优的混合网络结构。在不使用卷积或自注意力机制的情况下,提出的三维多层感知机结构在标准数据集上超过了广泛使用的三维卷积神经网络和视频Transformer,同时只需要更少的计算量。
30
Putting People in their Place: Monocular Regression of 3D People in Depth
单目人体3D重建及深度预测
对于任意一张包含多个人的图像,我们的任务是直接从中预测所有人的3D姿势、形状、以及他们的相对深度。然而,当缺少人体高度的先验信息时,从单张图像预测人与人的相对深度通常是模糊不准确的,尤其是场景中包含从婴儿到成人不同身高并且紧密排列的多个人。
为了解决这个问题,首先,我们提出了一种基于鸟瞰图(BEV,Bird's-Eye-View representation)的3D表征方式,与以往基于图像平面的2D表征不同,BEV 同时推理图像平面和深度方向的人体中心位置,由此形成相机空间中的人体3D位置。不同于现有的多阶段算法,BEV使用端到端可微分的单阶段网络。其次,由于人的身高随年龄变化,如果年龄未知,则无法准确解决图像中人的相对深度估计问题。
为此,我们设计了全年龄段的3D人体模型空间,BEV 能够预测出从婴儿到成人的全年龄段人体形状。最后,为了有效训练模型,我们构建了"Relative Human" (RH)数据集,标注了年龄、姿态、人与人的相对深度关系等丰富信息。在RH 和 AGORA 数据集上的大量实验结果表明,我们的算法BEV 在深度预测、儿童3D形状预测,以及遮挡等复杂场景下,都具有优越的性能。

31
Gait Recognition in theWild with Dense 3D Representations and A Benchmark
基于密集三维表征的真实场景步态识别
现有步态识别研究主要关注于人体轮廓序列或关键点序列等二维特征表达。然而,人们生活(行走)在三维空间中,将三维人体投影到二维平面会丢失许多步态识别所需的视角、体型和步态的动态信息等关键信息。
因此,本研究旨在探索真实场景下基于密集三维表征的步态识别,这一具有实际应用价值却被忽视的问题。我们提出一个探索3D人体骨骼蒙皮模型(3D Skinned Multi-Person Linear(SMPL) model)在步态识别上可行性的新框架,称为SMPLGait。SMPLGait通过两个精心设计的分支,分别从人体轮廓中提取外观特征,及从3D SMPL中学习三维视角和体型的先验知识。此外,由于缺乏合适的数据集,我们构建了第一个基于三维表示的自然场景大规模步态识别数据集,名为Gait3D。它包含4000个行人对象和超过25000个步态序列。
Gait3D采集自一个无约束的真实室内场景中的39个摄像头,提供了从视频帧中恢复的3D SMPL数据,可支持密集人体体型、三维视角和步态动态信息的三维建模。此外,它还提供了二维人体轮廓和人体关键点数据,可帮助研究者们探索多模态步态识别。基于Gait3D,我们全面比较分析了本文提出的SMPLGait方法和现有步态识别方法,实验结果不仅证明我们的方法具有更好的步态识别准确性,也显示出三维特征表示在真实场景的步态识别问题中的巨大潜力。

32
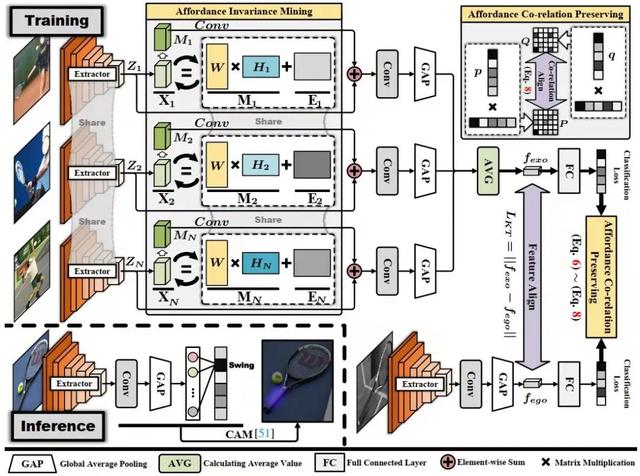
Learning Affordance Grounding from Exocentric Images
从第三人称视角图像中学习物体可供性标定
可供性标定(affordance grounding)是定位物体上动作可能性区域的一种任务,由于存在多样的交互从而导致难以与物体局部区域建立显式的联系。但是,人具有从多样的第三人称交互迁移到第一人称下不变的可供性特征来抵御多样的交互带来的影响的能力。为了使得智能体具有这样的能力,本文提出了一个从第三人称视角学习可供性标定的任务,即给定一张第三人称视角的人-物体交互图像和一张第一人称视角的物体图像,仅利用可供性标签作为监督,从第三人称视角的图像中学习可供性知识,并迁移到第一人称视角中。
为此,我们提出了一个跨视角知识迁移框架,从第三人称视角的交互中提取可供性相关的知识,并通过维持可供性的共生关系增强网络对可供性区域的感知能力。具体地,一个可供性不变特征挖掘模块通过最大限度地减少第三人称视角图像中由交互习惯所产生的类内差异来提取特定的线索。
此外,还提出了一种可供性共生关系保留策略通过对齐两个视角预测结果之间的共生关系矩阵来感知和定位可供性区域。特别地,通过收集和标记了超过2万张来自36个可供性类别的图像来构建了一个名为AGD20K的数据集。实验结果表明,我们的方法在客观指标和视觉质量上均优于其他代表性方法。
33
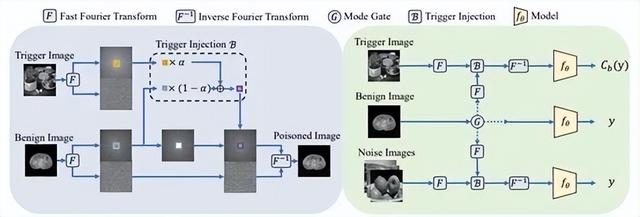
FIBA: Frequency-Injection based Backdoor Attack in Medical Image Analysis
FIBA:医学图像分析领域中 基于频域信息注入的后门攻击
近年来,人工智能系统的安全性引起了越来越多的研究关注,特别是在医学成像领域。为了开发安全的医学图像分析(MIA)系统,对可能存在的后门攻击(backdoor attack, BAs) 的研究不可缺少,这种攻击可以在系统中嵌入隐藏的恶意后门。然而,由于医学图像成像模式(如x线、CT和MRI图像)和分析任务(如分类、检测和分割)的多样性,设计一种适用于各种MIA系统的统一的后门攻击方法颇具挑战性。
现有的后门攻击方法大多是针对自然图像分类模型进行攻击,将时域触发器直接应用于训练图像,不可避免地会破坏受污染图像部分像素的语义,导致对密集预测模型的攻击失败。为了解决这个问题,我们提出了一种新的基于频域信息注入的后门攻击方法(FIBA),能够在各种MIA任务中进行攻击。
具体来说,FIBA设计了一个频域触发器,通过线性组合两幅图像的频谱振幅,将触发图像的低频信息注入有毒图像。由于FIBA保留了受污染图像像素的语义,因此既可以对分类模型进行攻击,也可以对密集预测模型进行攻击。我们在医学图像领域的三个基准上进行了实验(用于皮肤病变分类的ISIC-2019数据集,用于肾脏肿瘤分割的KiTS-19数据集,以及用于内镜伪像检测的EAD-2019 数据集),以验证FIBA攻击MIA模型的有效性以及其在绕过后门防御方面的优势。
34
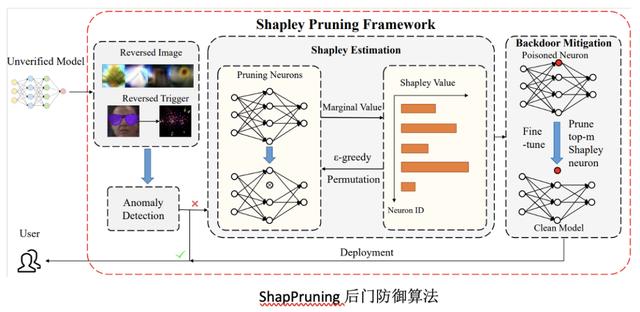
Few-shot Backdoor Defense Using Shapley Estimation
基于夏普利估计的小样本后门防御
神经网络在诸多领域有着广泛的应用,但已有研究表明神经网络容易遭受后门攻击,造成潜在安全威胁,因此后门防御是一个非常重要的问题。已有后门防御工作通常需要较多训练数据并剪除大量神经元,这些防御算法容易破坏网络原本结构并依赖于来网络微调操作。为了更高效准确地去除神经网络中的后门攻击,我们提出一种基于Shapley value的ShapPruning后门去除算法。
ShapPruning利用触发器逆合成估计后门触发器,并通过蒙特卡洛采样以及epsilon-greedy算法高效估计神经网络中各神经元与网络后门攻击行为的关联程度,从而准确定位后门感染神经元,进而更精准的指导后门去除。
相较于之前研究,我们的工作可以在每一类只有一张图片的情况下去除后门攻击,同时印证了后门攻击只通过感染神经网络中极少数神经元(1%左右)实现网络操纵。同时,我们采用data-inverse的方法,从感染模型中恢复训练数据,提出了一种无数据的混合模式ShapPruning算法,实现了无数据的神经后门去除。我们的方法在数据缺乏情况下,在CIIFAR10, GTSRB, YouTubeFace等数据集上针对已有后门攻击方式均取得了很好的效果。

如若转载,请注明出处:https://www.yiheng8.com/95437.html
 微信扫一扫
微信扫一扫 相关推荐
-
京东的趋势好物是什么(京东的趋势分析)
最近,高瓴重仓中概股的消息传开,当实情公布后,最令人惊讶的还是它分别重仓了京东和唯品会。其中,唯品会翻倍增持、京东持仓升至第二。 要知道,高瓴资本在业内被称为“投资风向标”,也可以…
-
京东快递寄件服务电话,京东快递寄件服务电话是多少?
京东快递是国内知名的电商平台之一,同时也提供强大的快递物流服务。相信很多人都有通过京东快递进行包裹寄送的经历,但可能还有不少人对于京东快递寄件服务电话不够了解。本文将为大家介绍京东…
-
京东商城客服电话是多少号(京东商城客服电话人工95118)
平台网购杰克琼斯夹克,被商家欺瞒欺骗欺诈,弱小的消费者何以维权? 4.10日,我在京东平台购买了4件杰克琼斯的衣服。收到货后,我试了试,感觉有3件不合适,当时就申请了退款。 由于迟…
-
京东国际物流一般要几天,京东国际多长时间到货?
跨境电商物流作为电商领域的中坚力量和坚强的合作伙伴,物流的不畅通一直都是跨境电商最大的软肋,虽然近年来跨境电商发展迅猛,但物流方面却频频传出爆仓、延误、禁运的消息且频率越来越高。保…
-
京东运营兼职(京东运营新手教程)
七天万评原理是什么?七天万评听起来跟一单百评有异曲同工之妙,其实这二者都是刷单方法,都是在短时间内进行大量留评,将一款产品推到首页。但是众所周知,刷单是违规行为,加上平台审查更加严…
-
网络信息安全论文5000字开头(网络信息安全论文5000字数多少)
网络信息安全是涉及计算机科学、网络技术、通信技术、密码技术等多种学科的综合性学科。伴随人类社会正加速进入网络信息时代,人们对网络信息系统的依赖程度也不断加深。现如今,网络信息安全已…
-
京东有几种支付方式(京东可以用什么付款方式)
?本文原创,请勿抄袭和搬运,违者必究 数字人民币试点版已经上线了,这也意味着在微信,支付宝之后,国内又将多了一种新型支付方式。作为央行发行的数字货币,其影响力甚广,因此许多国内互联…
-
京东618跟双11比哪个优惠力度大,京东是618还是双十一优惠大?
家电一年之中什么时候才是最便宜的呢?作为普通老百姓,我们的原则是花最少的钱,买最放心的东西。而行业而言,电器行业销售途径就2种,线上和线下。 1、线上: 电商最大的两个节日是618…
-
京东店铺入驻流程,京东店铺入驻流程有哪些?
作为国内最大的综合性电商平台之一,京东商城拥有着众多优质的商家和海量的用户群体。因此,很多商家都想要把自己的店铺开在京东上,以获得更大的曝光和更多的交易机会。那么,今天我们就来了解…
-
电商平台的设计与实现论文,基于电商的网页设计毕业论文?
想象一下走进一家零售店寻找一些新的工作服。当您环顾四周时,您注意到地板上有污渍、杂乱无章的架子和奇怪的气味。您会留在商店并从零售商处购买吗? 商店设计会影响顾客的行为方式——网站也…