在「个性化图像美学评价」领域,现有方法主要基于图像中所呈现的客观内容进行个性化建模。然而个性化图像美学评价的本质是度量图像所呈现的客观内容被不同的用户主体感知时所激发的美学感受。
因此,图像的客观内容与用户的主观特性共同作用,进而产生差异化的美学评价结果。相应地,理想的个性化图像美学评价模型,也需要同时使用图像内容和用户的主观信息。然而,由于缺乏标注丰富且包含主观信息的数据集,个性化美学评价算法研究进展缓慢。
近日,OPPO研究院联合西安电子科技大学李雷达教授,结合美学、心理学、用户画像信息等知识,提出了主客观信息融合的个性化美学评价新范式,并开源了带有丰富属性标注的个性化美学评价数据集PARA,为建模个性化审美偏好提供了崭新的思路和数据可能。
论文已被CVPR 2022收录,数据集地址:https://cv-datasets.institutecv.com/#/data-sets
突破学科限制,利用心理学知识设计AI数据库
图像美学评价旨在通过计算机对图片的“美丽程度”进行打分。根据审美是否考虑个性偏好,业界将图像美学评价的分为两类:通用和个性化。前者依赖「平均」概念,反映大众美学审美;后者需要考虑到个人独特的审美特点,反映个人的“千人千面”。
与通用图像美学评价相比,个性化图像美学评价也需考虑主观特性、客观属性等更全面的因素,覆盖不同用户审美感知的多样性,具有更加直接的应用价值。但由于当前该领域数据集的标注维度缺乏多样性,个性化图像美学评价的研究面临一定程度的科研挑战性。
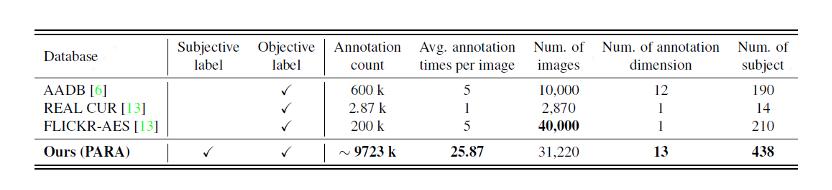

图注:PIAA数据集之间的比较。此前的主流数据集缺乏主观信息的标签,标注维度和数据规模相对较小。
为了解决上述难题,OPPO研究院和西安电子科技大学的研究人员利用“跨学科、先验知识”等思维设计了相关数据集和模型。
本文任务
通过丰富的属性标注,实现更加全面的个性化图像美学评价。
本文创新
1.使用跨学科的思维设计了包含主观和客观属性的数据集;
2.通过数据分析探讨主观和客观标注维度的关联性;
3.利用用户画像作为“先验知识” ,提出条件PIAA 建模方法。
回答业界关心问题
1.数据集如何保证多样性以及解决偏差?
从健康状况、工作经历、个体性格、个人画像四个方面来选择标注人员,保证人员多样性;在从Flickr下载约28,000张CC0图片的基础上,从Unsplash网站和SPAQ、KonIQ-10K等主流图像质量评估数据集添加大约 3,000 张具有明确美学共识的图像,保证语义和分数分布相对平衡。
2.主观信息中的个人性格特征如何确定?
使用心理学领域权威的BFI-10 人格调查问卷进行用户摸底,然后计算大五人格特征分数,并添加到标注维度中。
3.如何证明数据库的可用性和优越性?
可用性:baseline模型的个性化美学评价结果比较准确,测试指标较好。
优越性:设计两种基准模型:有条件和无条件的PIAA。实验结果显示:加入用户画像信息一组的实验结果高于对照组,证明通过加辅助信息可以超越仅利用美学分数学习的模型。
4.“先验知识”在个性化图像美学评估中能起到什么作用?
建模时加入了三种条件信息,包括个人性格、美学经验以及摄影经验。实验结果显示:利用主观属性信息进行PIAA建模可以提高模型性能。
强调主观信息,探究美学评价与个性化之间的相互作用
数据集设计原则
数据集制作分为四步:图片收集、标签设计、人员选择以及主观实验。
图片收集过程中,使用了场景识别模型预测每张图片的场景标签,然后人工修正保证标签质量;随后根据场景标签采样收集了31,220张图像。
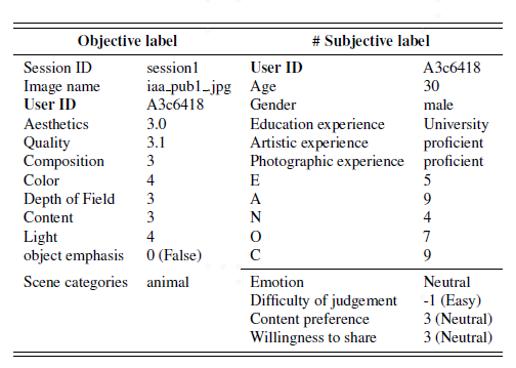
图注:单张图片的标签信息。分为主观、客观两类,通过User ID识别。
在参考已有美学评价主流数据集的基础上,设计的标签如上表所示,每张图片的一条“打分”记录都包含13个属性标签以及相关联的用户画像信息。13个属性标签包含9个客观属性(例如图像美学、情感等),4个主观属性(例如内容偏好、分享意愿等)。
人员选择的原则是保证被试人员的质量和多样性,研究员从健康状况、标注经历、用户画像以及培训考核等方面选择“入库人群”。例如,只有具有一定标注经验,身心健康的个体,且通过每日的标注培训和考核后,才可以进行数据标注。
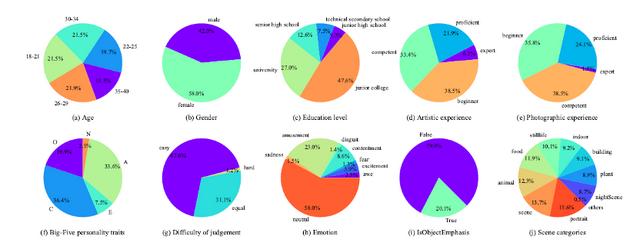
图注:数据库统计分布信息
主观实验遵循心理学主观实验规范。研究员将整个数据库分成446个标注会话,每个标注会话包含70张待标记的图像,5张有标记的图像(提前多人标注作为标准图校验标注是否符合通用标准),以及5张重复的图像(需要打两次标注的,从而测试标注的一致性)。
数据分析结果
通过分析数据集,研究员发现,每个美学属性的分布是相似的,但也存在微小的差异,这表明各个美学属性相互关联的同时,每个维度仍然能够提供独特的信息。如美学评分(4,5)区间比其他区间有更低的方差,这意味着对 "什么是美 "有共同的认知,但存在不同的审美观点。
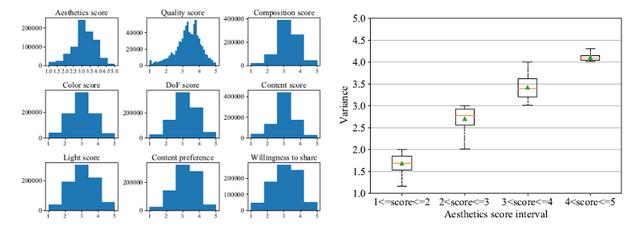
图注:(左)标签分数的分布;(右)美学得分箱线图
同时,进一步分析发现,个体性格、美学评分和美学属性之间具有相关性。例如具有 "神经质(Neuroticism)"性格的受试者倾向于对外部刺激作出过度反应;“内容偏好”和“分享意愿”维度高度相关,证明人们在喜好图片内容时更容易分享照片。
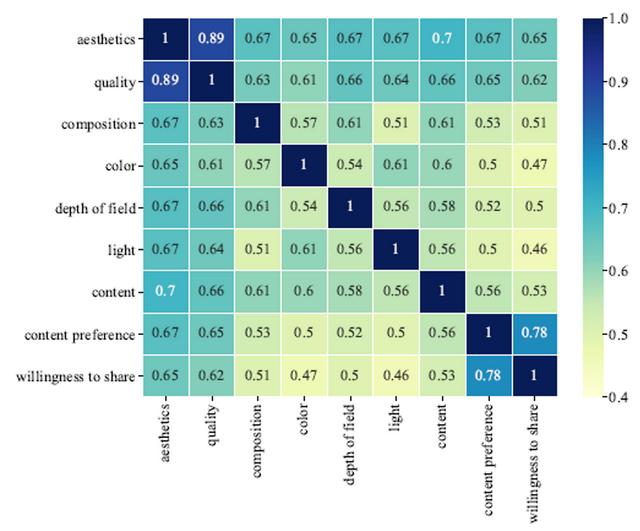
图注:属性维度之间的相关系数
基准模型设计
最后,为了证明数据集的可用性和优越性,研究员对数据集进行了基准模型研究。包括有条件和无条件的 PIAA两种建模方法,训练方式如下图所示。
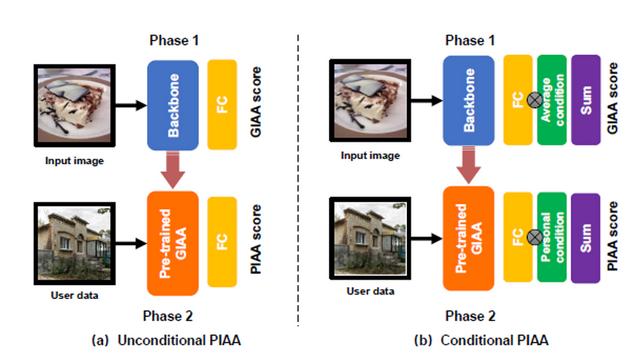
PIAA模型产生于通用美学评价模型(GIAA),区别之处在于:使用个人数据微调,强调学习个性化偏好。相比无条件的PIAA模型,条件 PIAA 建模时分别添加了三种条件信息,包括个体性格、美学经验和摄影经验。由于 PIAA 是一个典型的小样本问题,研究员们参考 零样本学习以及之前的相关工作进行实验设置,例如分为三组:无微调组(“对照组”)、10-shot 组、100-shot 组。
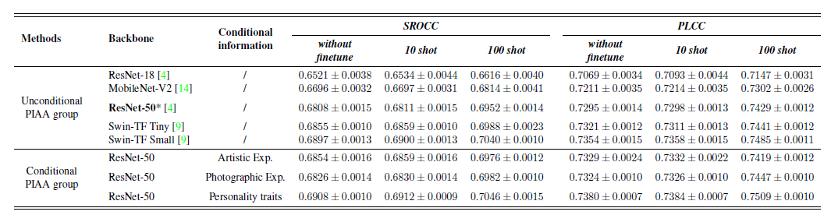
图注:在 PARA 上提出的有条件和无条件 PIAA 的实验结果
实验结果显示,通过对10-shot 组和100-shot 组的个性化数据进行微调,PIAA的表现可以超过对照组;更多的个性化训练数据可以进一步提高微调的性能;与无条件的PIAA组相比,利用主观信息进行PIAA建模可以提高模型性能。
结语
美学评价类相关研究任务具有很强的主观性,不同的个体有不同的美感认知,通用的美学评价在建模时忽略了个体审美主观性。针对个性化图像美学目前存在的主观性问题,本文提出了结合用户画像信息以及丰富的标注维度的个性化美学评价算法,并开源了所使用的个性化图像美学评价数据集PARA,打破个性化美学评价学术研究的思路和数据壁垒。
未来,OPPO研究员会将该数据集以及相关技术应用到相册、相机、互联网内容理解等实际场景中,从而为用户打造更极致的个性化体验。
Project Page: https://cv-datasets.institutecv.com/#/data-sets

如若转载,请注明出处:https://www.yiheng8.com/90979.html
 微信扫一扫
微信扫一扫 相关推荐
-
拼多多新用户助力网站在线刷最便宜(拼多多新用户代刷网站)
抖音店铺拉新效率增长较慢怎么办?想要进一步强化用户优惠感知,促进下单?联合新享升级为店铺新人礼金,混资、全资的双重选择,高效提升新客转化,为品牌汇聚更多增长机会! 一、什么是店铺新…
-
卡思数据app下载官网(卡思数据下载)
编辑导语:前段时间爆火的“张同学”,过了热度期也开始掉粉了,乡村网红似乎都难逃昙花一现的命运,变现难、曝光度降低,都是眼下亟待解决的问题。本文作者分析了这一现象,一起来看看吧。 曾…
-
虾皮app官网下载马来西亚(虾皮app官网下载卖家)
虾皮是毛虾加工制成的一种虾干,上乘的虾皮一般个头较大且虾体完整。本期推荐这款赶海弟脱水虾皮,生虾晒干含盐量少,干吃、煮汤都很鲜香。 赶海弟 脱水虾皮 盖得测评员总结 赶海弟脱水虾皮…
-
地推资源对接平台,地推项目网站?
前言:地推中遇到的场景多种多样,主要需要结合推广的行业以及推广的形式选择适合自己的话术,针对各种场景行业需要灵活应变。 所谓话术,可以理解为是一个推广发言总纲领,一定要注意活学活用…
-
在家代加工项目官网,可靠的在家代加工项目?
芒果干 这是很多人都爱吃的一种零食,在广西百色市有这样一家芒果干加工厂,它生产的纯天然无添加的芒果干比普通芒果干色泽更亮,外形均匀不开裂,甜度更柔和,甜中带酸,酸中带香,很有层次感…
-
嘉兴兼职招聘信息网站,嘉兴兼职招聘网最新招聘?
来源:【嘉兴日报-嘉兴在线】 怎样更好地守护咱们老百姓的“钱袋子”?知己知彼才能百战不殆。今天,记者从嘉兴市反诈人民战争领导小组办公室拿到了今年1至7月嘉兴地区的反诈大数据。一起看…
-
扑克王德州平台下载,扑克王德州平台下载网站是多少?
如何下载并使用扑克王德州平台 在现如今的科技发达的社会,线上扑克游戏越来越受到人们的欢迎。扑克王德州平台下载是一款备受瞩目的德州扑克游戏平台,今天我们就来了解一下如何下载并使用扑克…
-
中建云筑网集采平台官网,中建一局云筑网集采平台
近日,云筑优选2021年度华南区域(广东省、福建省、海南省、江西省、广西壮族自治区)MRO供应商集中招募投标已开启。本次区域采购招标在投标保证金支付阶段同样开通了投标履约保险支付,…
-
抖音官方电话24小时人工服务热线口不对心的人,抖音官方投诉电话24小时人工服务热线?
#心动的瞬间#3月31日,乔任梁的爸爸在清明节前去给儿子扫墓,并在抖音发布了视频记录下来。视频里解释因为乔妈的腿病犯了,所以这次只有乔爸过来。 乔老爷在视频中写道:又一年清明时节,…
-
全网诚信刷,诚信刷会员网站?
来源:【长春日报-长春新闻网】 “岳阳居民要记牢,诈骗花样真不少。个人信息最重要,密码账号保管好……不存贪心烦恼少,一旦被骗没得找。”近日,一段朗朗上口的反诈“顺口溜”在南关区曙光…