分屏显示函数
split.screen(c(2,2))
[1] 1 2 3 4
> screen(1)
> qqnorm(x)
> screen(2)
> qqplot(1:100,x)
> screen(3)
> curve(dnorm(x),xlim=c(-3,3))
> screen(4)
> curve(pnorm(x),col='red')
> curve(qnorm(x),col='red') #不会自动移到screen(1);仍然在4重复显示。
close.screen(all = TRUE)
split.screen(c(2, 1)) # split display into two screens
split.screen(c(1, 3), screen = 2) # now split the bottom half into 3
screen(1) # prepare screen 1 for output
curve(dnorm(x),tck=0.01,las=1,col.axis='blue',col='red')
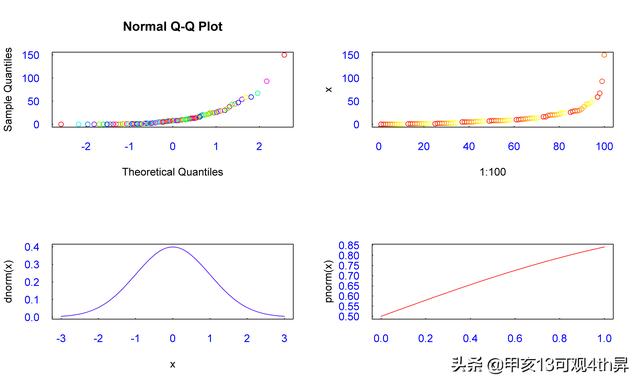


分屏显示函数比起par()方式的最大优点:前者可以跨区域绘制图形,例如上图中,在2号分屏上,可以实现在跨越3、4、5号分屏上绘图。
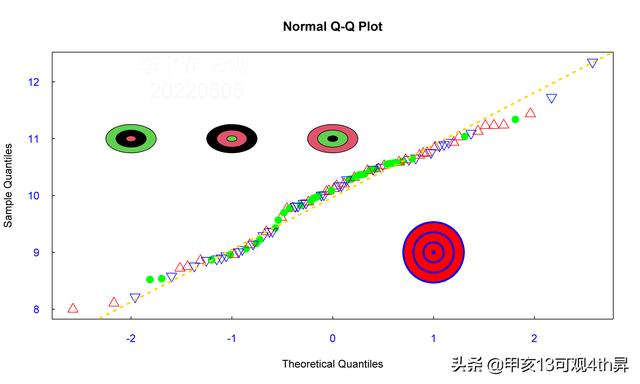
QQ图绘制
画曼哈顿图和QQ图的方法和软件有很多,不过最方便的还是R语言的qqman包。
install.packages('qqman')
library(qqman)
head(ccc)
SNP CHR BP P
1 rs1072111 157 125299.64 0.02725910
2 rs1072112 8 28284.27 0.05370998
3 rs1072113 21 45825.76 0.02331393
4 rs1072114 156 124899.96 0.02751106
5 rs1072115 83 91104.34 0.05612848
6 rs1072116 33 57445.63 0.06033141
> manhattan(ccc)
qq(x);qq(w);qq(w/70)
QQ图的方法2:
#如果不使用第三方包,最简单的方法就是下面这样:
qqnorm(x,col=c('red','blue','green'),las=1,col.axis='blue',tck=0.01,cex=1.6,pch=c(2,6,16))
qqline(x,col='gold',lwd=3,lty=3)
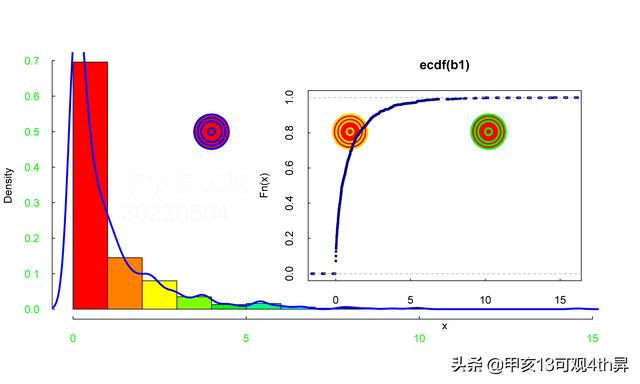
可视化数据——概率分布的密度图
对于数据分布的另外一个可视化方式则是密度图;在概率密度图中,试图通过绘制适当的连续曲线(核密度曲线)来可视化数据的潜在概率分布。
#概率=概率密度*组距
hist(w, freq = FALSE)
lines(density(w), col = "blue") # density是核密度曲线
#频数=概率*总样本数
概率=概率密度*组距;概率密度=概率/组距;
在概率密度直方图中,取到任一bin中的一个样本的平均概率,等于该箱的高度(纵坐标y值) × 宽度(横坐标间距δx) ÷ 该箱中样本个数(n_samples),而不是等于纵坐标y值;即此时面积表示概率之和,而不是纵坐标y值表示单一样本概率;
在累积分布直方图中,取到任一bin中的一个样本的平均概率,等于(该箱的高度(纵坐标y值) -左侧箱的高度)/ 该箱中样本个数;即此时纵坐标y值表示概率,但为累计概率。
怎样看懂直方图中体现的数据信息?
直方图是从总体中随机抽取样本,将样本数据加以整理,用于了解数据的分布情况,使我们比较容易直接看到数据的位置状况、离散程度和分布形状的一种常用工具。它是用一系列宽度相等、高度不等的长方形来表示数据,其宽度代表组距,高度代表指定组距内的数据数(频数)。
直方图的绘制还是和分组的多少(bin)有关;如果组数过多那么就会有很多条,如果组数过少则可能反映不出数据的正确的分布趋势。因此对于一个直方图的绘制,往往需要不断地去尝试不同的分组。
直方图的形状:
1.常态型:中间高、两边低、有集中边势,显示过程正常。
2. 离岛型:在右端或左端形成小岛。说明一定有异常原因存在,如数据收集方法错误、数据来源不同或新手作业违背操作规程等特殊原因,需迅速追寻原因,采取必要措施。
3. 双峰型:有两个高峰出现。两台不同的机器或两种不同原料间存在差异时,或者作业者不同时也可发生此类直方图。
4. 锯齿型:图形的柱形高低不一,呈现缺齿的形状。这种情况大多因为制作直方图的方法错误(如:数据分组问题、计算组距问题、计算界限问题等)或数据收集方法不正确(如:不同设备数据、不同人收集的数据、不同时段数据造成)产生。
5.偏态形:高处偏向一边,另一边低,拖长尾巴;可分为偏右型、偏左型。这种偏态分布理论上是规格值无法取得某一数值以下所致,在质量特性上并没有问题,但我们需要留意拖长的尾端在技术上是否可接受?
6.高原形:直方图的柱子高低近似,柱子间高度相差甚微,看起来有点像高原一样,则称为高原形;当数据来自几种平均值差异不大的产品,而这些产品有混在一起时,制作出来的直方图往往就是高原形,应层别之后再作直方图比较。
直方图形状与规格的对应关系分析
规格又分为双侧规格(同时有上下限的要求)和单侧规格(只有上限或下限的要求,如时间数据、分值数据等);直方图与规格比较时又分为符合规格和不符合规格两类:
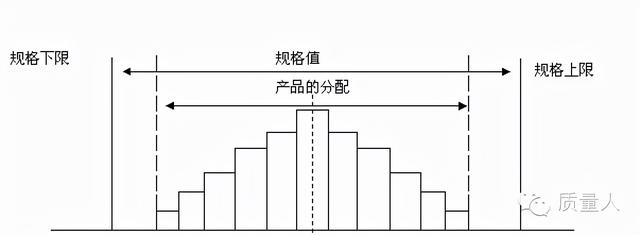
符合规格:
1.理想型:规格值的平均值与产品的分布平均值重合,而且直方图的下限与上限均在规格值的上下限范围之内,直方图的下限与规格值的下限、直方图的上限与规格值的上限之间的距离为4个标准差左右,这样的直方图时最理想的直方图。
2.一侧无余裕:产品的分布均在规格值范围内,但是偏向上限或者下限分布,造成单侧拥塞,另一边余裕很多。
3.两侧无余裕:产品分布的下限与规格下限重合,分布上界限与规格上限重合,即分布与规格恰好相等。虽没有不良发生,但过程稍有变动,就有不良品发生的风险。
4.余裕太多:也就是过度集中,该类产品分布的范围较小,而规格值的范围太大,也就是说制程的能力远远大于规格的要求。
不符合规格:
1.平均值偏左(或偏右):也叫单边不良形,表示平均位置有偏差,应考虑过程的能力不足,需寻找系统原因,纠正平均值位置,提高品质水平。
2. 分散度过大:也可称为双边不良形。产品的最大值与最小值均超过规格值, 有不良品发生表示标准太大, 制程能力不足。
3.离岛现象:有“离岛”产品出现,且发生不良现象,说明过程有异常原因存在,应调查离岛的原因,判明离群原因(通常为特异原因)并予以去除。
“复合”直方图的绘制
#先绘制概率密度图及核密度曲线
hist(x,breaks=10,col=rainbow(10),tck=0.01,col.axis='blue',prob=T,main='')
lines(density(x),col='red',lwd=3,lty=3)
#添加“复合”的2号直方图
par(new=T)
hist(x,col=terrain.colors(10),tck=0.01,col.axis='blue',axes=F,ann=F,main='')


如若转载,请注明出处:https://www.yiheng8.com/98141.html
 微信扫一扫
微信扫一扫 相关推荐
-
如何提取QQ群成员,开展数据库营销!
当我们创建了一些QQ群,或者添加了一些其它用户的QQ群,如果我们想记录潜在QQ群里的用户,开展数据库营销或者后期跟进,这时就需要提取QQ群成员!
-
一打开快手就跳转三方应用怎么关掉,快手怎么关闭跳转功能?
“快应用”是无需下载安装的,类似于小程序一样的轻应用,即搜即用。 听起来很便捷的样子呀,应该给手机节省了不少的内存吧,就不需要安装一大堆的app了。 可是,为啥它被很多用户吐槽,称…
-
qq转账怎么强制退款(qq转账能申请退款吗)
为深入践行“三项承诺”,充分保障胜诉当事人的合法权益,浙江法院以政法队伍专项教育整顿和党史学习教育为契机,深入剖析案款管理中存在的问题,制定科学合理的指导方案,开展案款顽瘴痼疾专项…
-
抖音qq登录怎么跳过绑定手机号,抖音qq登录怎么跳过绑定手机号没有跳过怎么办?
标题:抖音QQ登录跳过绑定手机号的方法大揭秘!描述:许多人在使用抖音QQ登录时,不希望绑定手机号码,那么该怎么跳过呢?本文将为大家揭示方法,让你轻松实现QQ登录,无需手机号。关键词…
-
广告的功能有什么(广告的功能都有什么)
在我们青春的记忆里,曾经在电视里听到过这样的几乎家喻户晓的广告词:“燕舞,燕舞,一片歌来一片情。”这是一个男生唱的广告词。是为当年的燕舞牌收录机做的广告。 这个广告,大概是在…
-
微信怎么彻底删除视频号功能,微信怎么彻底删除视频号功能设置?
微信是当今社交网络中最受欢迎的应用之一,它不仅提供了聊天、朋友圈和视频通话等基本功能,还有一个备受关注的功能——视频号。然而,有时候用户可能需要彻底删除微信视频号功能或重新设置该功…
-
qq群拉人网站平台(推广qq群的网站)
法制周报讯(通讯员 任齐天)当前,电信网络诈骗持续高发,电话卡、银行卡被骗子购买后实施诈骗,给警方追查和打击造成很大困难。冬春攻势以来,常德市公安局武陵分局打击帮助信息网络犯罪人员…
-
抖音团购功能怎么开通,抖音团购功能怎么开通需要付费不?
随着社交电商的火热,短视频平台抖音也加入到团购热潮中来。抖音团购功能上线后,迅速受到广大商家的欢迎,尤其是在疫情期间,很多实体店都转战线上,并通过抖音团购来增加销量和转化率。 那么…
-
qq很火的吓人短视频下载一关灯就出现女鬼,QQ吓人的视频?
提示:阅读本文约3分钟! 近日,新加坡社交媒体流传一段视频,一名女网红到有“地狱别墅”之称的虎豹别墅园区游览时,爬上雕塑区,还到处乱摸,对雕塑做出不雅动作,引起众多网友不满。 视频…
-
QQ邮箱后面字母怎么打,qq邮箱前面加什么字母?
文/潘鸣 有一种感觉一一但愿是错觉:我的故乡川西平原,一座座乡间庭院,竹影婆娑的情景,正在悄然与日消褪。新建的院舍许多变身为小洋楼,再配以幽幽纤竹,似乎不搭调,品质上差层次了;从实…