前天陈某知识星球中的朋友咨询过我一个问题,大致内容如下:

这位读者什么意思呢?简单的总结下:在Sharding-JDBC中明明只是简单的使用@Transactional这个本地事务注解,为什么在跨库插入数据时候却能够同时回滚?
我们知道单数据节点的情况下保持事务是非常简单的,只需要使用本地事务即可轻松解决,比如常用的注解:@Transactional
但是在分库后将会存在跨库的事务,此时本地事务还能保证事务吗?
这篇文章就以球友的提问来聊一下Sharding-JDBC中的本地事务
本地事务
Sharding-JDBC中的本地事务可能会让大家有一个误解,还是以商品表为例:将商品表根据商品ID进行水平分库,分为两个库,如下:
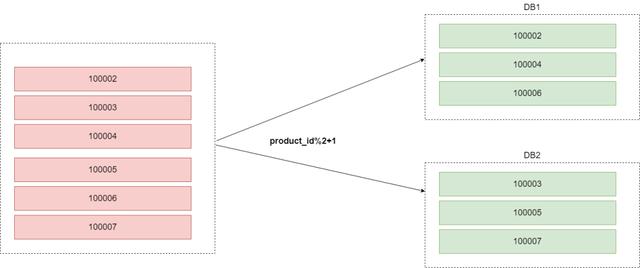
分库的配置这里就不贴了,详情看源码
此时向其中批量插入数据,伪代码如下:
@Transactional
public int insertBatch(){
for(int i=0;i<10;i++){
insert(product);
.......
}
}
上述案例中使用了@Transactional开启了本地事务,但是内部在插入数据时,Sharding-JDB会根据product_id这个分片键进行分库,那么这个业务方法肯定是跨了DB1、DB2这两个库,@Transactional这个注解能解决吗?
假象:手动在内部模拟抛出异常,还真的是都rollback了
此时很多人都迷糊了,Sharding-JDBC中的本地事务真的是可以保证分布式事务?
“
真实结论:Sharding-JDBC中的本地事务无法保证分布式事务
”
Sharding-JDBC中的本地事务在以下两种情况是完全支持的:
- 支持非跨库事务,比如仅分表、在单库中操作
- 支持因逻辑异常导致的跨库事务,比如上述的操作,跨两个库插入数据,插入完成后抛出异常
本地事务不支持的情况:
- 不支持因网络、硬件异常导致的跨库事务;例如:同一事务中,跨两个库更新,更新完毕后、未提交之前,第一个库宕机,则只有第二个库数据提交
对于因网络、硬件异常导致的跨库事务无法支持很好理解,在分布式事务中无论是两阶段还是三阶段提交都是直接或者间接满足以下两个条件:
- 有一个事务协调者
- 事务日志记录
本地事务并未满足上述条件,自然是无法支持
为什么逻辑异常导致的跨库事务能够支持?
Spring的本地事务大家都很了解,也经常用,并不支持的跨库事务,那么为什么Sharding-JDBC中却能支持呢?
想要了解其中的猫腻必然需要从Sharding-JDBC的源码入手,下图是在Sharding-JDBC一条SQL处理的流程:
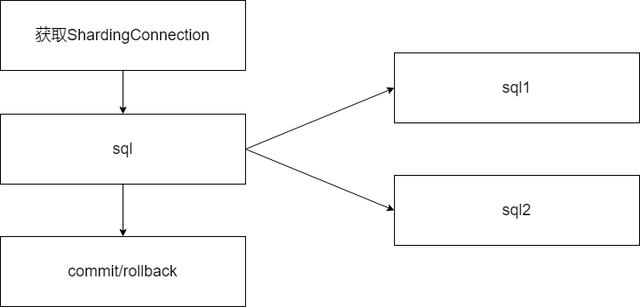
Sharding-JDBC中的一条SQL会经过改写,拆分成不同数据源的SQL,比如一条select语句,会按照其中分片键拆分成对应数据源的SQL,然后在不同数据源中的执行,最终会提交或者回滚
想要解释上述的问题,只需要看ShardingConnection,这是Sharding-JDBC自定义实现的,继承关系如下图:
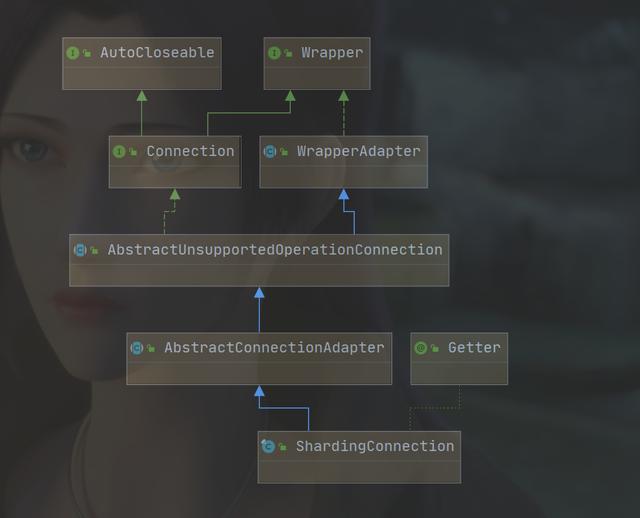
可以看到ShardingConnection继承了java.sql.Connection,这个类就不必多解释了,在学习JDBC的时候应该都有所接触,直接和数据库打交道的一个类。
想要知道为什么支持跨库事务的回滚,肯定要找到其中的rollback方法,如下:
@Override
public void rollback() throws SQLException {
//① 本地事务
f (TransactionType.LOCAL == transactionType) {
super.rollback();
} else {
//② 非本地事务
shardingTransactionManager.rollback();
}
}
rollback的方法中区分了本地事务和分布式事务,如果是本地事务将调用父类的rollback方法,如下:
//父类:AbstractConnectionAdapter#rollback
@Override
public void rollback() throws SQLException {
//cachedConnections中存储了数据源,这里是ds1/ds2
forceExecuteTemplate.execute(cachedConnections.values(), Connection::rollback);
}
这里是调用ForceExecuteTemplate#execute()方法执行,其实内部就是遍历数据源去执行对应的rollback方法,如下:
public void execute(final Collection<T> targets, final ForceExecutecallback<T> callback) throws SQLException {
Collection<SQLException> exceptions = new LinkedList<>();
for (T each : targets) {
try {
callback.execute(each);
} catch (final SQLException ex) {
exceptions.add(ex);
}
}
throwSQLExceptionIfNecessary(exceptions);
}
看到这里已经很明了了,rollback 在各个数据源中回滚且未记录任何事务日志,因此在非硬件、网络的情况下都是可以正常回滚的,一旦因为网络、硬件故障,可能导致某个数据源rollback失败,这样即使程序恢复了正常,也无undo日志继续进行rollback,因此这里就造成了数据不一致了。
总结
仅仅依靠Spring自带的本地事务(@Transactional)是无法保证跨库的分布式事务,不要被Sharding-JDBC的假象迷惑了。
当然Sharding-JDBC对于跨库事务也是有一定的支持,大致分成三类:
- 强一致性的XA协议事务
- 基于Base的柔性事务
- 通过SPI机制自定义扩展的分布式事务解决方案
本文只是抛砖引玉简单的介绍下分库分表后的事务处理,后文会针对以上三类方案详细介绍一下。
来源:https://mp.weixin.qq.com/s/yzkCC_jnSF5AUHlkOKd4XA

如若转载,请注明出处:https://www.yiheng8.com/83322.html
 微信扫一扫
微信扫一扫 相关推荐
-
拼多多延长收货可以延长几天_,拼多多延长收货可以延长一天吗?
一般要5~10天左右拿到,新车牌制作就要3到5天,邮寄也要3到5天送到。 车牌制作一般要3-5个工作日 由于部分车辆号牌是还没有做出来的,那么车管所造车牌就需要花费一点时间,制作好…
-
拼多多店铺转让后入驻人信息(拼多多店铺转让过户)
随着疫情,想着在拼多多开店能挣点钱。交了1000保证金,结果多多天天还想挣你得钱。 第一,广告费。刚开始一开店有送广告费,一开起来还是有单的,但是不开广告就没单了。 第二,罚款。有…
-
对父母愚孝是什么意思(愚孝是什么意思怎样解释)
图片来自网络 掌权者淫威下的“孝顺?” 孝顺,即顺老人的意。对于社会各个阶层,各种年龄,不同性别,不同受教育程度的人来讲都一样,那就是势必要牺牲一部分真实自我。 从孩子时起,人通常…
-
wifi网络需要wpa 2密码(需要wpa2密码啥意思)
在无线安全中,无线密码只是最基本的加密办法,选择适当的加密级别才是最重要的,正确的选择将决定无线 LAN 是稻草屋还是坚韧的堡垒。 无线安全协议不仅可以防止随意的人连接到无线网络,…
-
拼多多上的商品id是什么意思(拼多多商品id有什么用)
编辑导语:针对不同的用户人群和使用场景,设计师需要作出对应考量,以提升用户体验,更好地契合用户需求。本篇文章里,作者就对如何提升虚拟校园产品的用户体验案例做了分析解读,一起来看看吧…
-
抖音流量密码是什么意思网络用语,抖音流量密码是什么意思呀?
网络时代,尤其是自媒体时代,媒体与个人作者,都在竭尽全力寻找流量密码。 但究竟什么是流量密码呢? 对于不同年龄的人来说,是不一样的。 比如现在60岁以上的人,那代人,他们喜欢的是谈…
-
网络无法连接服务器是什么意思(打电话无法连接服务器是什么意思)
在2022年这个炎热的夏天,国内外最火的暗黑系列续作莫过于最新推出的《暗黑破坏神:不朽》了,众多冒险者都选择在这个夏天重返庇护之地,又可以一起在副本里一刷一下午了,怎能不让人异常激…
-
下头男下头女啥意思(下头男是什么意思网络用语)
老板当到什么份上才算惨? 出个差回来,最信任的员工自立门户了,走就走吧,还搬器械、毁合同、抢资源,甚至还神不知鬼不觉地带走了所有的员工…… 这位史上最惨老板不是别人,正是网红博主“…
-
支付宝风控是什么意思,多久会消除(花呗风控是什么意思,多久会消除)
各家银行都有一套自己的风控系统,一般是用来监测持卡人的消费情况,其实就是在给客户“画画像”,所谓的用户画像,其实就是持卡人的消费习惯。通过客户刷卡,来掌握持卡人的消费习惯,如果某一…
-
拼多多营销词有哪些,电商营销词有哪些?
现在的电商竞争非常激烈,我们不仅要展示出优质的产品还要学会运营店铺,这样才会给自己的店铺带来更多的流量。在运营店铺时,很多商家避免不了对产品做营销策划,在产品展示时做好营销类表述,…